












.webp)
Value discovered
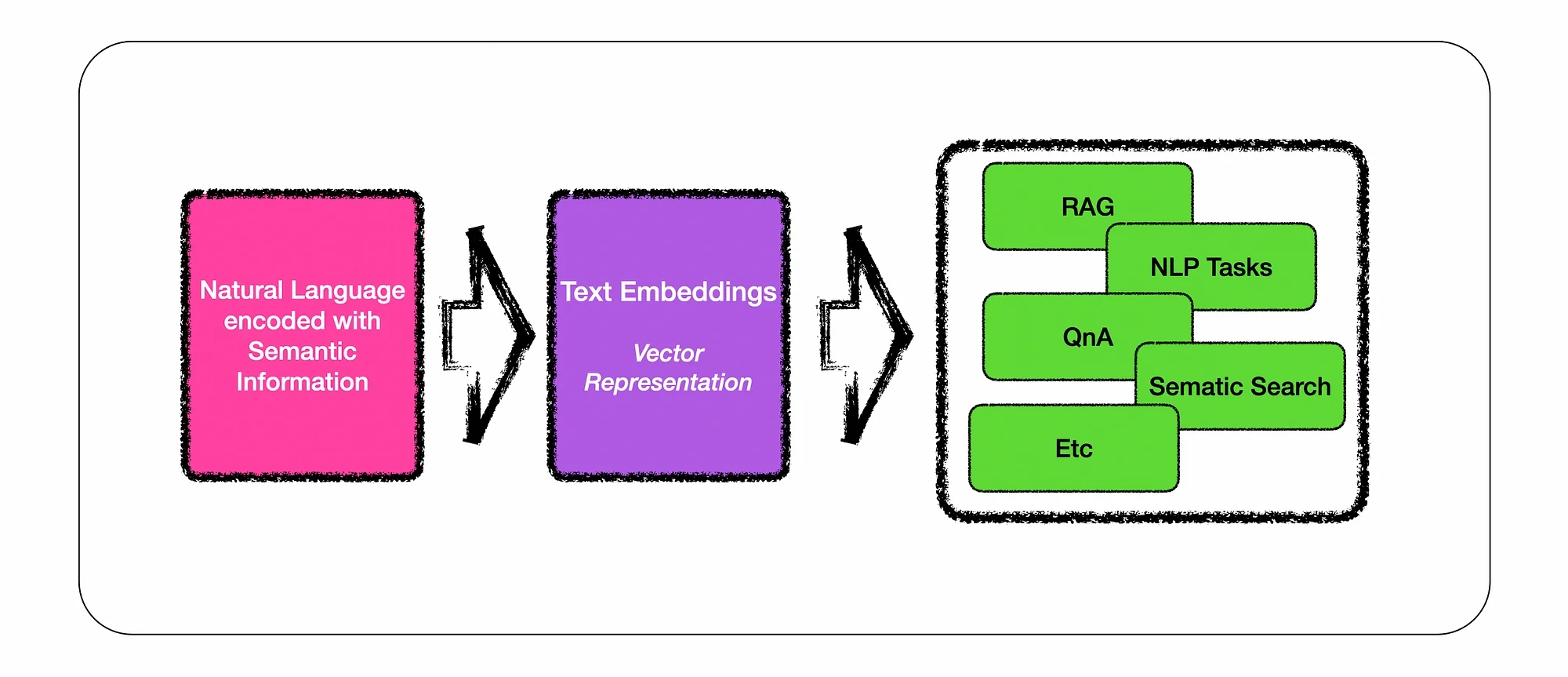
Text embeddings are really playing a pivotal role in retrieving semantically similar text for RAG implementations and in-context learning at inference.
This study focusses on creating high quality text embeddings by only using synthetic data and only executing 1,000 training iterations.
Generally available LLMs were used to generate synthetic data for 100,000+ of text embeddings across a multitude of tasks and languages.
Experiments demonstrate that our method achieves strong performance on highly competitive text embedding benchmarks without using any labelled data. — Source
Solved challenge
Embedding-based retrieval is the foundational component of retrieval-augmented generation (RAG). RAG has been proven as a highly effective approach to allow LLMs to reference dynamic external knowledge at inference without training the base model.
The study wanted to solve for the challenge of creating large amounts of weak-supervised text pairs, building complex training pipelines or manual collection of datasets which need to be annotated.
The two overheads to collecting data for large RAG implementations are:
- Complex multi-stage training pipeline that demands substantial engineering efforts to curate large amounts of relevant pairs.
- Manually collected datasets that are often constrained by the diversity of tasks and the coverage of languages.
- This new approach does not rely on any unlabelled documents or queries and thus can generate more diverse synthetic data.
Considerations
There a few considerations to keep in mind…
- Due to commercial interests and product marketing and fit, certain approaches are favoured and pushed above others. This study is again a reminder that the tools and methods at our disposal are growing and enterprises will have to select the right technology, processes and people for each task.
- This study addresses the challenges when semantic search and similarity tasks are implemented on a very wide range of data. For instance, the study considered 93 different human languages and ranging over 100,000s of embedding tasks. Hence the sheer scale of the endeavour should be taken into account.
- I say this, because there are many very capable no-code to low-code semantic / text embedding tools available where reference data can be uploaded via a web interface. And subsequently data is automatically chunked in vector representations are created. But I get the sense this study is focussing on very large scale implementations.
- There is also a requirement from most organisations to understand and gain insights from existing customer conversations. And being able to create user and conversation intents from past conversations; hence solving for the long-tail of intent distribution.
- Hence synthetic data is not be seen as the silver bullet while neglecting Reinforcement learning from human feedback, or any form of weak supervision.
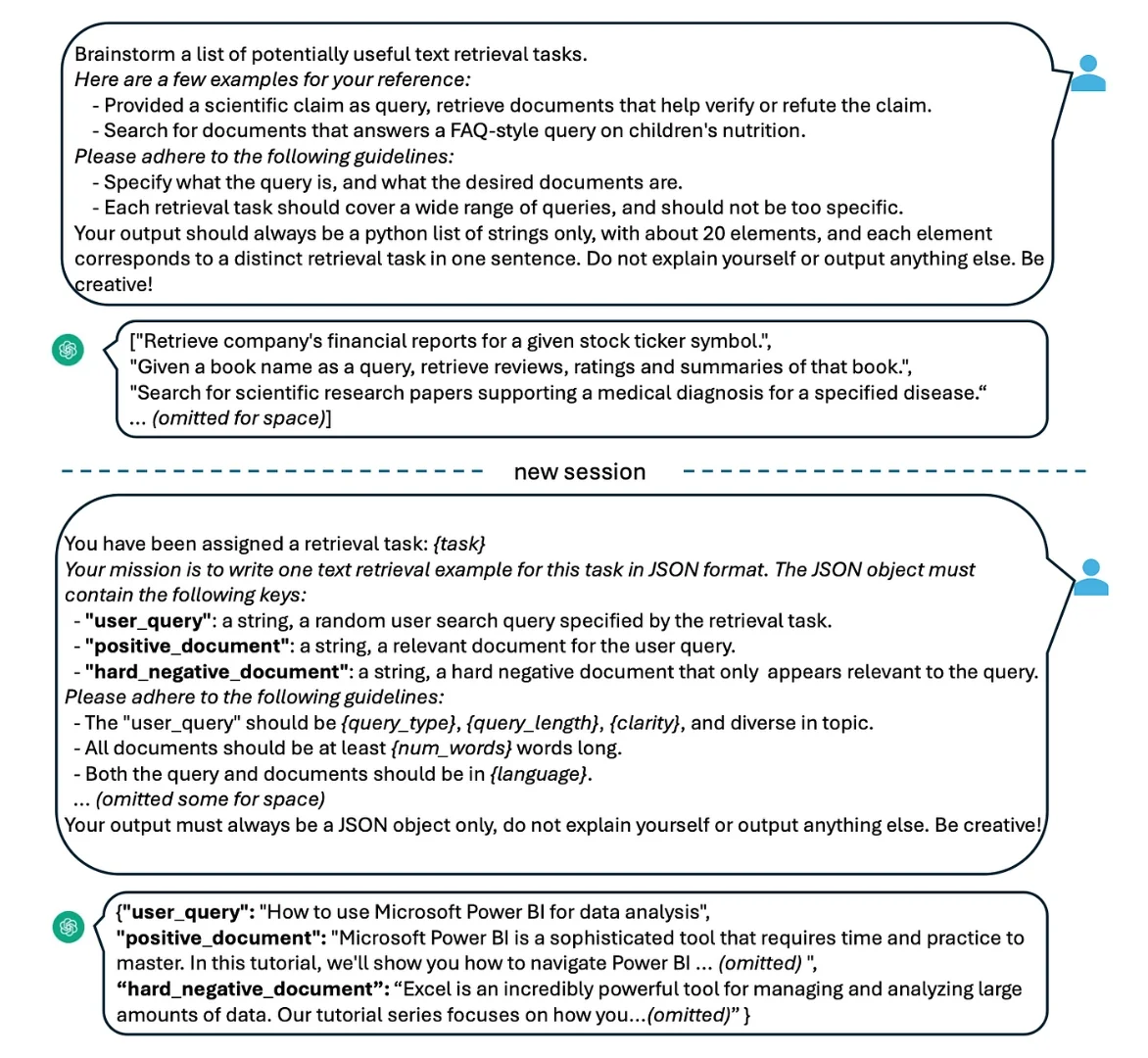
- Considering the image below, it is clear that this approach follows a two-step approach and the templates are shown below. Synthetic data was created using GPT-4.
- The first prompt is used to brainstorm a list of potential retrieval tasks and then generate (query, positive, hard negative) triplets for each task.
- The templated process makes for ease of automation, but cost will be high for generating vast amounts of training data.
- I guess there is a case to be made, to take existing vetted and annotated data and augment this data. Especially based on the same user intent and possibly branching out into other languages.
Creating diverse synthetic data
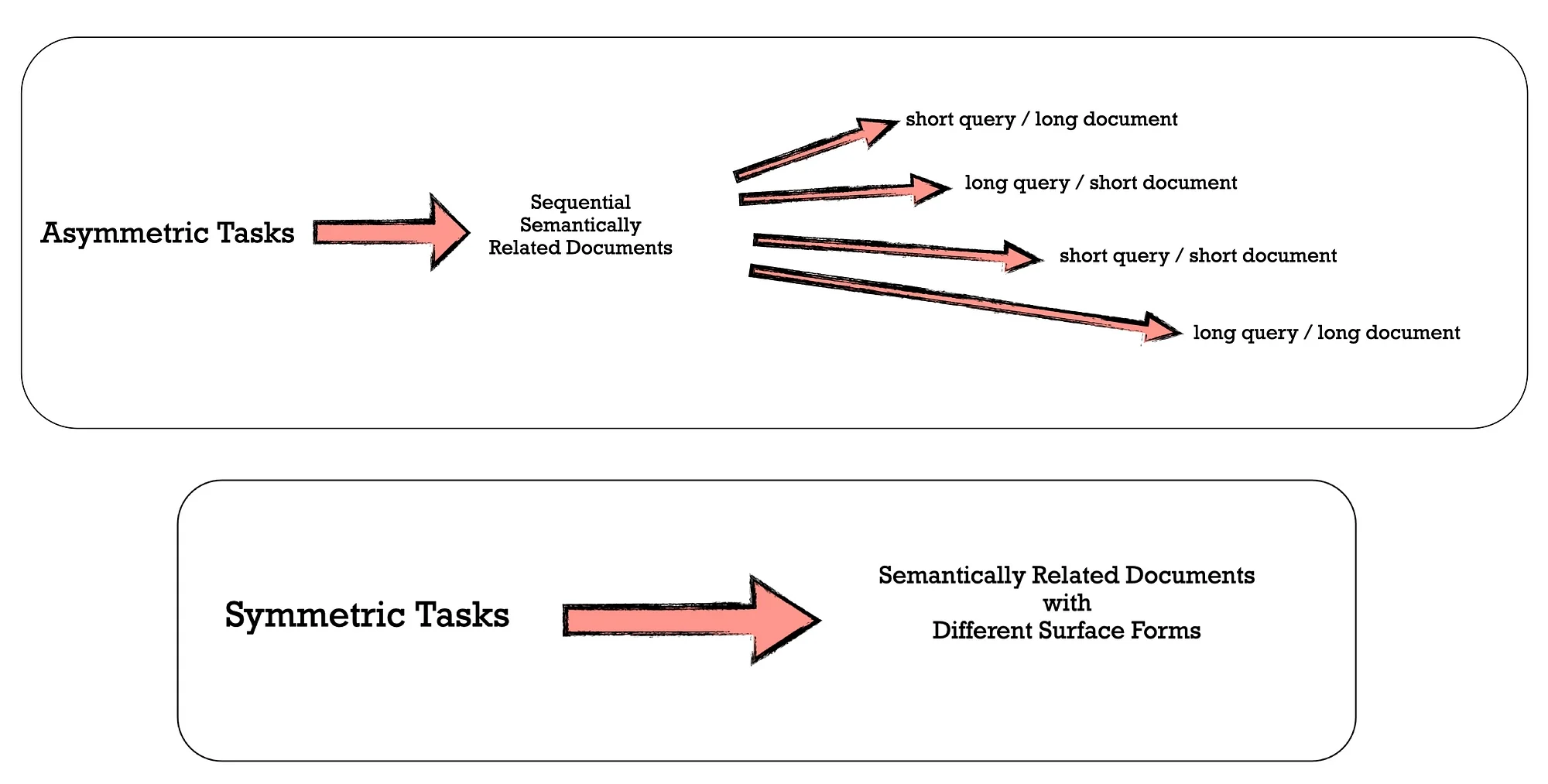
To generate diverse synthetic data, the study developed a taxonomy that categorises embedding tasks into several groups, and then apply different prompt templates to each group.
As illustrated below…
Below the statistics of the synthetic data. The task type and language representation of the generated synthetic data are shown.

To again emphasise the scale of this exercise, with 500,000 examples and 150,000 unique instructions using Azure OpenAI Service, among which 25% were generated by GPT-35-Turbo and others are generated by GPT-4.
The total token consumption was about 180,000,000.
In terms of data quality, the study found that portions of GPT-35-Turbo outputs did not strictly follow the guidelines specified in the prompt templates.
Nevertheless, the overall quality remained acceptable, and preliminary experiments have demonstrated the benefits of incorporating this data subset.
Conclusion
The paper highlights the significant improvement in text embeddings’ quality by leveraging Large Language Models (LLMs), particularly proprietary ones like GPT-4.
The taxonomy to generate diverse synthetic data across multiple languages is insightful, and can be useful on a smaller scale.
Future direction includes enhancing multilingual performance, exploring open-source LLMs for synthetic data generation, and investigating methods to improve inference efficiency and reduce storage costs for LLM-based text embeddings.
Previously published on Medium.





