











.webp)
A CTO’s view on re-architecting the SDLC with guardrails, review loops, and a text-driven control plane ,so AI can move from assistive tooling to a trusted engineering participant.
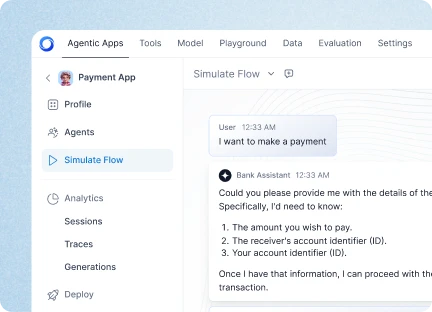
We’ve spent the past few months building something fairly ambitious: a deeply AI-native system, while also increasingly letting AI participate in how that system gets designed, reviewed, tested, and implemented. That experience has changed how I think about autonomous engineering.
I don’t think autonomous engineering starts when a model can generate a lot of code. I think it begins when we can build an engineering system around the model that keeps the work grounded, reviewable, and recoverable over time. That is the part I want to talk about.
This is not a post claiming we have fully solved autonomous engineering. We haven’t. We’re still early, still learning, and still correcting our assumptions. But we’re far enough in to see the shape of the problem more clearly, and I think that matters.
The biggest lesson so far is simple:
“Autonomous engineering is not a model problem. It is a systems problem.”
The goal isn’t more AI, it’s better engineering with AI
When AI first starts writing code inside a real engineering workflow, the first reaction is usually excitement, and rightly so. It can move fast, cover ground, and generate surprising amounts of useful material.
But if you stop there, you end up optimizing for output volume instead of engineering quality.
We learned pretty quickly that the most important question is not “Can AI generate code?” The more important question is “Can the resulting work stay real as the task gets larger?” That is where things get interesting.
At a small scale, a model can look amazing. It writes a handler, adds a test, and explains itself well. But, at engineering scale, new problems show up. Tests pass only because the boundary that actually matters was mocked out.. Code exists, but it is not really wired into the system. A task looks complete in the diff, but the route isn’t mounted, the middleware chain is never exercised, or the integration path is still broken.
You also start to see duplication. The same logic shows up across files because the model did not find or trust the original abstraction. And over time, specs say one thingtests assume other, and implementation ends up somewhere in between
That pattern is more dangerous than obvious failure.
The real risk isn’t code that is broken or clearly wrong. The real risk is output that looks right at glance without being operationally true.
That is why I’ve increasingly come to see this as a control-plane problem.
Text became the control plane
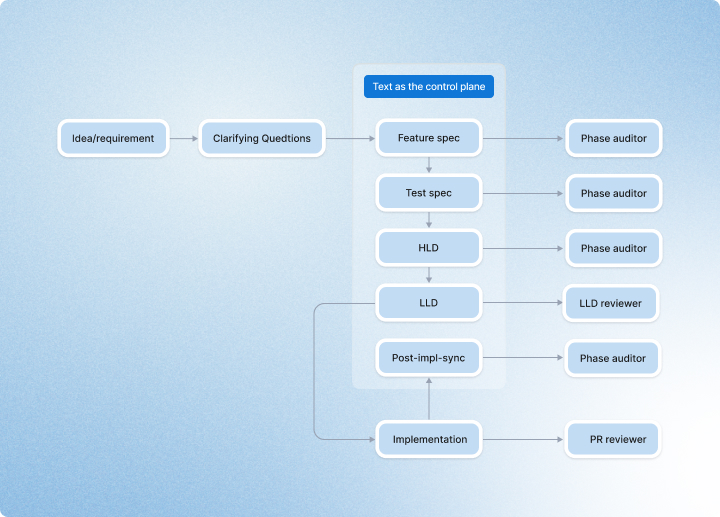
The single biggest change in our thinking was moving from “documentation” to text as the control plane. That phrase has become foundational for us.
Feature specs, test specs, HLDs, LLDs, implementation plans, review logs, and post-implementation sync are not documents we write after the real work is done. They are the mechanism that keeps the work aligned while the real work is happening. The reason this matters is simple: prompt context is not durable to serve as the source of truth for long-running engineering work.
The longer the task, the more likely it is that earlier decisions blur, requirements get compressed into vague memories, and the model starts optimizing for local completion instead of system-level correctness. That is exactly where drift begins. Treating text as the control plane changes that.
The feature spec holds scope and requirements steady. The test spec defines what evidence will count before code gets written. The HLD captures architecture, boundaries, and tradeoffs. The LLD turns that into a phased implementation plan, file-level changes, wiring checkpoints, and exit criteria. Post-implementation sync forces the artifacts back into alignment with what was actually built.
Without that layer, everything lives inside a conversation. With it, the system has memory.
```mermaid
flowchart LR
A["Idea / requirement"] --> B["Clarifying questions"]
B --> C["Feature spec"]
C --> D["Test spec"]
D --> E["HLD"]
E --> F["LLD"]
F --> G["Implementation"]
G --> H["Post-impl-sync"]
C --> C1["Phase auditor"]
D --> D1["Phase auditor"]
E --> E1["Phase auditor"]
F --> F1["LLD reviewer"]
G --> G1["PR reviewer"]
H --> H1["Phase auditor"]
subgraph CP["Text as the control plane"]
direction LR
C
D
E
F
H
end
```That is why I increasingly believe autonomous engineering will only become practical when text becomes a first-class control surface rather than an afterthought. Once we started treating text this way, the SDLC stopped feeling like a ceremony and started feeling like infrastructure.
Clarifying questions made the designs better and reduced hallucinations
One of the most practical things we learned is that enforcing clarifying questions during design and planning leads to more comprehensive designs and materially reduces downstream hallucinations. We now force clarifying questions before writing a feature spec, test spec, HLD, or LLD. That is not a process for process’s sake. It is a way of forcing ambiguity to surface early, before the system starts filling gaps with convenient local assumptions.
If the planning phase does not address what the real boundary is, what the actual success criteria are, what the production entry point is, what the integration path looks like, or what must be true for the feature to be genuinely complete, then the implementation is much more likely to drift.
In practice, this changed the shape of our designs. They became broader in the right way - more complete, more grounded in the real system, and less likely to miss edge conditions, operational concerns, or integrations paths. And because ambiguity surfaced early, the implementation phase had fewer opportunities to invent its own version of reality. This was one of the clearest examples of a small process change having an outsized effect.
A few minutes of clarifying questions early on prevented a lot of downstream confusion.
Real E2E turned out to be one of the best feedback mechanisms for AI
Another major learning was around testing.
We found that real E2E testing is one of the most effective ways to give feedback to AI.
For API features, that means running end-to-end scenarios through actual HTTP APIs, without mocking codebase components, without direct DB access, and without bypassing middleware. Seed through the API. Assert through the API. Let auth, validation, scoping, serialization, and error handling all execute for real.
For Studio-facing use cases, browser-level testing became incredibly valuable. Playwright scripts gave us a way to exercise real authoring and configuration flows the way a user would actually experience them: navigation, edit paths, save/reload behavior, feature-gated states, and end-to-end UI journeys that can look “done” in code long before they are actually wired into the product.
That did two important things.
First, it made the model’s mistakes much more visible. When the system has to survive real API execution or a real browser journey, local plausibility stops being enough.
Second, it made the feedback far more actionable. Instead of “something seems off,” the agent gets a specific signal: this route is not reachable, this state does not persist, this path is not mounted, this UI save flow is incomplete, this feature works in isolation but not in the real application.
That is much better feedback than another mocked test suite telling us that everything is green.
We also learned that forcing the design and test phases to explicitly cover real E2E scenarios helped remove a surprising number of missing-wiring cases. Once the test spec had to answer, “How does this get exercised end-to-end through the real system?” it became much harder to forget the last mile.
In that sense, E2E was not just validation; it became a feedback loop for both design and implementation.
The ralph loop only works if auditors are real
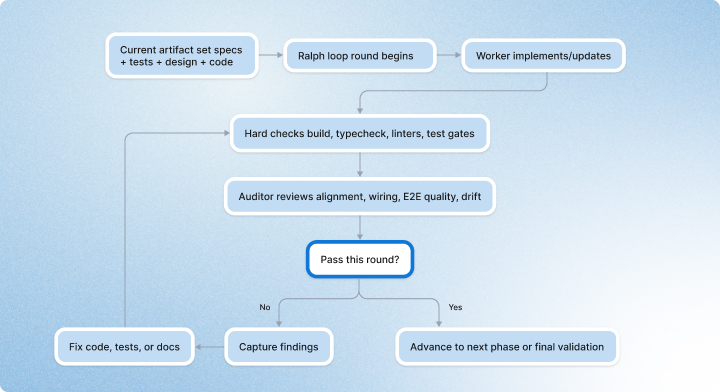
Another thing we learned is that loops are useful, but only if they create skepticism.
A plain retry loop is not enough. If the same agent generates the work, interprets the work, and reviews the work, it will often grade itself too generously. Not out of bad intent, but because the same assumptions that created the mistake are still present during the review.
So we started treating the Ralph loop not as “retry until it looks better,” but as a structured build-review-fix cycle where each loop iteration is effectively an audit round.
```mermaid
flowchart TD
A["Current artifact set<br/>specs + tests + design + code"] --> B["Ralph loop round begins"]
B --> C["Worker implements / updates"]
C --> D["Hard checks<br/>build, typecheck, linters, test gates"]
D --> E["Auditor reviews<br/>alignment, wiring, E2E quality, drift"]
E --> F{"Pass this round?"}
F -- "No" --> G["Capture findings"]
G --> H["Fix code, tests, or docs"]
H --> D
F -- "Yes" --> I["Advance to next phase or final validation"]
```That shift made a big difference.
Instead of treating iteration as a soft refinement tool, we started treating it as a quality mechanism. The reviewer’s job is not to admire the output. The reviewer’s job is to find what is still not real:
- Is the feature aligned to the spec?
- Are the tests exercising the actual system boundary?
- Is the wiring complete?
- Did we create a second source of truth?
- Is the implementation locally polished but systemically wrong?
That is a much more useful loop.
Clearing context turned out to improve review
One of the most counterintuitive lessons for us was that clearing context can improve quality.
At first glance, that feels backwards. If context is useful, shouldn’t more of it always be better?
In practice, long-running AI work degrades in subtle ways. Earlier assumptions get blended together. Stale decisions stay alive too long, and review becomes sympathetic to how the artifact was produced rather than f critical of the artifact itself. So we increasingly started forcing fresh reads from disk.
We generate an artifact, we write it down, clear or compact context, then spawn an auditor with fresh context and make it read the artifact from disk as the source of truth.
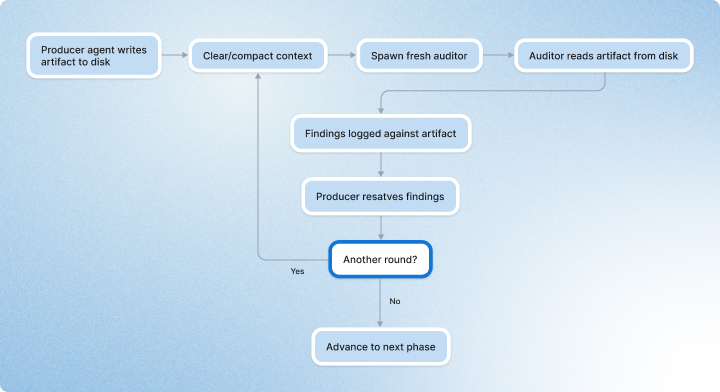
```mermaid
flowchart TD
A["Producer agent writes artifact to disk"] --> B["Clear / compact context"]
B --> C["Spawn fresh auditor"]
C --> D["Auditor reads artifact from disk"]
D --> E["Findings logged against artifact"]
E --> F["Producer resolves findings"]
F --> G{"Another round?"}
G -- "Yes" --> B
G -- "No" --> H["Advance to next phase"]
```Turns out, this matters a lot.
Fresh-context auditors are much better at catching drift, stale assumptions, and false completeness than reviewers that inherit the whole conversational history. Once we saw that clearly, it changed our operating model. Memory belongs in artifacts. Reviewers should start fresh as often as possible.
That has been one of the most practical lessons on the road toward autonomous engineering.
Model optimization matters, but it does not solve AI slop
Model choice absolutely matters. We have learned to route work more intentionally instead of treating model selection as an afterthought.
Anthropic positions Sonnet 4.6 as a strong default for coding, agents, and long-running tasks at scale, while Opus 4.6 remains its strongest model for the deepest reasoning and the most demanding tasks.
That framing lines up well with how we think about model routing in practice.
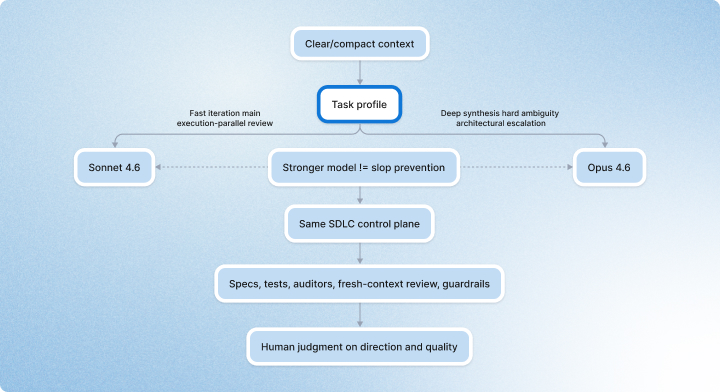
```mermaid
flowchart LR
A["Engineering task"] --> B{"Task profile"}
B -- "Fast iteration<br/>main execution<br/>parallel review" --> C["Sonnet 4.6"]
B -- "Deep synthesis<br/>hard ambiguity<br/>architectural escalation" --> D["Opus 4.6"]
C --> E["Same SDLC control plane"]
D --> E
E --> F["Specs, tests, auditors,<br/>fresh-context review, guardrails"]
F --> G["Human judgment on direction and quality"]
H["Stronger model != slop prevention"] -.-> C
H -.-> D
```In our experience, Sonnet-class models are often the right main driver for day-to-day execution: drafting artifacts, moving through implementation phases, handling repeated review loops, and supporting higher-throughput engineering work. Opus-class models are excellent when the task genuinely requires deeper synthesis, harder architectural tradeoffs, or recovery from ambiguity.
That routing pattern is also broadly consistent with Anthropic’s own positioning of the two model families. Having said that, we started seeing really great outcomes from Open AI GPT 5.4 with Extra High effort.
But there is an important qualifier here:
Opus 4.6 is great. It is not, by itself, a solution to AI slop.
A stronger model can absolutely improve reasoning depth. It can reduce some classes of mistakes. It can do better synthesis. But it does not eliminate the underlying failure mode where the work looks more complete than it actually is. In some cases, a stronger model can produce more convincing forms of slop because the output is more coherent, more polished, and harder to question on first read.
That is why I now think of slop as a systems failure more than a model-tier failure.
You do not stop slop just by buying a better model. You stop slop by building a better engineering system.
Guardrails are how learning becomes leverage
That belief shows up very concretely in how we now write and enforce rules.
Our internal AGENTS.md and CLAUDE.md files are full of instructions that might look operational or even mundane from the outside:
- Run the build before the test.
- E2E tests must not mock codebase components.
- Cross-scope access should return 404, not 403.
- Read the source before using any existing component, function, or type.
- Keep commits small, focused, and additive.
- Run typechecks continuously, not only at the end.
- Sync documentation after implementation so the text stays real.
These rules did not appear because we wanted more process. They appeared because the same failure modes kept showing up.
So we turned them into hooks, linters, and guardrails:
- E2E quality checks to block mocked “black-box” tests
- typecheck hooks to catch imagined APIs early
- isolation linters to catch missing scoping
- auth rules to stop ad hoc security paths
- commit-scope and deletion guards to reduce regression blast radius
- doc-sync steps so artifacts do not quietly rot
That is what progress looks like here.
Not fewer mistakes, but better conversion of repeated mistakes into reusable discipline.
Why I’m more optimistic than before
What makes me optimistic is not that the models are flawless. I’m optimistic because we no longer need to pretend they are. We can acknowledge the limits honestly and still move forward.
We can say: yes, models drift; yes, they overstate completion; yes, they can generate polished but incomplete work. And then we can ask the better question: What kind of engineering system allows imperfect AI to still produce real, reviewable, high-quality work?
That is the question we are trying to answer.
For us, the answer is starting to take shape:
- text as the control plane
- auditors as first-class participants
- fresh-context review
- model routing instead of model worship
- hard guardrails where repeated failure deserves automation
- and an SDLC that treats AI as a serious participant, not just a fast code generator
We are still early. We are still learning. We are still changing pieces of the system as we go.
But this feels like the right direction.
Autonomous engineering, at least in the form I believe is worth pursuing, is not a moment when humans disappear and AI takes over. It is a gradual shift where humans define direction, architecture, and quality, while AI takes on more of the execution inside a system designed to keep the work real.
That is the future we are working toward.
And the more we build, the more I believe the teams that treat this as a systems problem, not just a model problem, are the ones that will be ready for what comes next.






