












.webp)
Agent memory is not a feature. It is the architectural foundation that determines whether an AI agent can operate as a genuine collaborator or stay a sophisticated autocomplete.
Most organizations deploying AI agents today are solving the wrong problem. They focus on the model's quality: the accuracy of its responses, the breadth of its training data, and the speed of its inference. These things matter. But they are not what determines whether an AI agent creates lasting value in an enterprise context.
What determines lasting value is whether the agent can learn. Whether it remembers. Whether it becomes more useful with each use. That capability has a name: agent memory. And despite being one of the most consequential design decisions in any agentic AI deployment, it remains one of the least understood.
The stateless problem: Why ai agents forget
Here is something worth sitting with for a moment. Every time you interact with a large language model, it starts from a blank slate. It processes what is placed in front of it, generates a response, and retains nothing. No record of who you are. No memory of what was discussed yesterday. No accumulated understanding of the organization it is supposed to be serving. This is what researchers call the stateless AI agent problem.
For a single-turn query, this is largely invisible. Ask it to summarize a document, draft an email, or answer a factual question, and statelessness has no real consequence. The task begins and ends in one session.
But enterprise workflows are not single-turn. A customer's relationship with a bank spans years of interactions. An employee working with an internal AI assistant builds up context over months. A procurement process moves through dozens of steps across multiple sessions. In all of these cases, statelessness is not a minor inconvenience. It is a structural failure. The agent cannot build on what came before, cannot recognize what has changed, and cannot adapt to the person it is working with.
An AI agent without memory is not a collaborator. It is a very capable stranger who has to be reintroduced every single day.
The business consequences are well documented. Context discontinuity, which is the failure of AI agents to retain user context across interactions, is consistently cited as one of the primary reasons AI deployments stall after initial pilots. Users who experience this friction do not file technical complaints about memory architecture. They simply stop using the tool.
What Is agent memory?
AI agent memory is the system that allows an AI agent to encode information from interactions, store it durably, retrieve it when relevant, and update it as conditions change. It is not a single feature. It is an architectural layer that sits alongside the model itself and determines what the model knows at any given moment.
The field has converged on a useful framework for thinking about AI agent memory types, drawn from cognitive science and adapted for modern AI systems. There are four categories, each serving a distinct function.
Semantic memory: What the agent knows
Semantic memory is the repository of facts that the AI agent has learned and kept. Who the user is. What their role involves. What terminology mean in this specific organization? What preferences have they expressed over time? Semantic memory is the foundation of personalization. It is what allows an agent to respond to a returning user with genuine relevance rather than generic output.
Episodic memory: What the agent has experienced
Episodic memory is the record of what has actually happened. Past interactions, their sequence, their outcomes. An AI agent with strong episodic memory knows not just what a user prefers, but what they have tried, what worked, what did not, and what was promised in earlier conversations. This is the memory type most critical for long-running tasks and multi-step workflows where continuity is everything.
Procedural memory: How the agent behaves
Procedural memory consists of the encoded behaviors, rules, and guidelines that govern how the agent operates. Communication protocols, escalation logic, compliance constraints, and organizational policies all live here. Procedural memory is what ensures an AI agent behaves consistently and appropriately within a given context, not just intelligently.
Working memory: What the agent knows right now
Working memory is the agent's active context window: everything it can see in the current moment. Working memory is temporary and bounded by the size of the context window, but it is where all the other memory types converge. Relevant facts from semantic memory, pertinent history from episodic memory, and applicable rules from procedural memory are all retrieved and assembled here before the agent responds.
The distinction that matters most in practice is between short-term memory for AI agents, which is what the agent knows within the current session, and long-term memory for AI agents, which is the persistent store that survives between sessions and is retrieved on demand. Designing agent memory is fundamentally about managing this boundary intelligently.
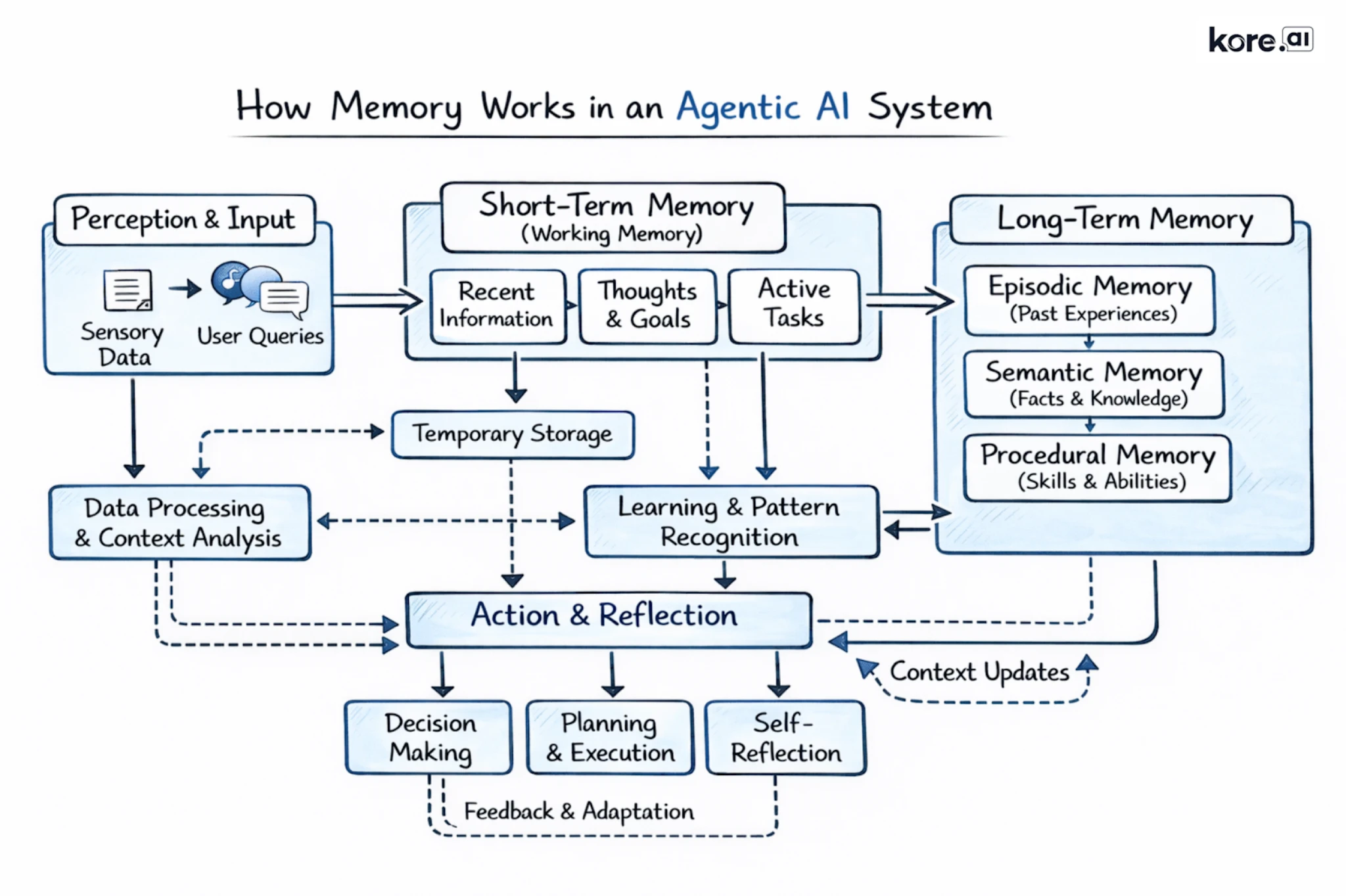
How does AI agent memory work? The four-stage pipeline
Understanding the agent memory conceptually is one thing. Building it well is another. Four interdependent processes determine whether a memory system genuinely improves agent performance or simply adds infrastructure overhead.
Stage 1: Extraction
Not everything that comes up in a conversation deserves to be remembered. Effective AI agent memory systems apply judgment at this stage, identifying facts, preferences, decisions, and outcomes that are likely to be relevant in future interactions, while discarding noise. The quality of this judgment directly shapes the quality of everything downstream. A poorly calibrated extraction layer leads either to bloated, noisy memory stores or to impoverished ones that fail to retain what actually matters.
Stage 2: Storage
Extracted information needs to live somewhere accessible. Vector databases, which organize information by semantic meaning rather than exact keywords, are the most common storage mechanism for persistent AI agent memory. They allow the agent to retrieve memories that are relevant to a query even when the phrasing differs from how they were originally recorded. For more complex, relationship-rich knowledge, graph databases offer the ability to store not just facts but the connections between them, enabling more sophisticated reasoning over time.
Stage 3: Consolidation
Memory systems accumulate contradictions. A preference changes. A fact becomes outdated. A new policy supersedes an old one. Without consolidation, the process of comparing incoming information against existing records and resolving conflicts, agent memory degrades. The system must determine whether new information should be added, used to update an existing record, or discarded as redundant. Memory systems that skip this stage tend to become liabilities as they scale.
Stage 4: Retrieval
When the agent is ready to respond, it searches the memory store for relevant information and pulls it into the active context window. Retrieval quality is where most AI agent memory systems succeed or fail in practice. Retrieving too much floods the context with noise. Retrieving too little leaves the agent under-informed. The best retrieval systems surface what is genuinely relevant to the current moment quickly enough not to degrade response latency.
The AI agent memory pipeline is only as strong as its weakest stage. Organizations that invest in storage infrastructure without investing equally in extraction quality and consolidation logic will find their memory systems becoming less reliable, not more, as they accumulate data over time.
Why building agent memory is harder than it looks
The case for agentic memory is obvious in theory. The implementation challenges are less visible, and underestimating them is one of the most common mistakes organizations make when deploying AI agents at scale.
The staleness problem
Information changes. A user's role, budget, preferences, and circumstances evolve continuously. An AI agent memory system that stores information without managing its freshness will, over time, provide the agent with confidently stated but incorrect context. Addressing staleness requires explicit lifecycle management: tracking when memories were created, monitoring for contradictory updates, and invalidating records that are no longer accurate.
The noise problem
Memory stores that grow without disciplined consolidation become progressively noisier. As the volume of stored information increases, retrieval surfaces more irrelevant results alongside relevant ones. The agent's effective context degrades even as the amount of stored data grows. Aggressive deduplication and merging at write time is the solution, but it requires investment in consolidation logic that many early implementations skip.
The governance problem
When an AI agent remembers user information, that data is subject to regulatory obligations. GDPR, CCPA, and a growing body of privacy legislation grant users rights over their stored data, including the right to access it, correct it, and have it deleted. Enterprise agent memory architecture must treat stored memories as first-class data objects with explicit metadata: source, timestamp, confidence, and lifecycle status. This is a design requirement from day one, not a compliance layer to be added later.
The Multi-Agent problem
Enterprise AI deployments increasingly involve networks of specialized agents operating in coordination. Each agent may need access to shared user context, but with appropriate boundaries. A customer-facing service agent should know a user's account history. It should not have access to sensitive data from an unrelated HR interaction. Memory scoping, which defines what each agent can read and write, requires architectural decisions that many organizations defer until they are forced to address them by an incident.
Agent Memory vs. RAG: What Is the Difference?
Retrieval-Augmented Generation, or RAG, is a powerful and widely deployed technique. It is also frequently confused with agent memory in ways that lead to underinvestment in persistent memory systems, so it is worth drawing a clear line between the two.
RAG gives an AI agent access to a knowledge base at the moment of inference. It retrieves relevant documents and injects them into the prompt, grounding the response in external information the model was not trained on. RAG is read-only. The knowledge base does not change based on user interactions. Every user draws from the same corpus. The agent does not learn from what it experiences.
Agent memory is fundamentally different. It reads and writes. It changes based on what users do and say. It is personal, specific to a user, a team, or an organization, rather than universal. And it compounds: the more the AI agent is used, the more it knows about the context it is operating in.
RAG gives every user access to the same encyclopedia. Agent memory gives each user their own record, one that grows more accurate and more useful with every interaction.
The two are not mutually exclusive. The most capable enterprise agent architectures use both: RAG for broad organizational and domain knowledge, and persistent AI agent memory for the user-specific and interaction-specific context that makes responses genuinely relevant. But they are not substitutes. Organizations that treat RAG as sufficient for their memory needs are solving only half the problem.
How Kore.ai Builds Agent Memory for the Enterprise
Kore.ai builds agent memory as a native, first-class capability within its Agent Platform. Within Agentic Apps, memory is implemented through a structured Memory Stores architecture that gives enterprise teams precise control over what agents remember, for how long, and for whom.
Two Memory Types, Working in Tandem
The platform supports two distinct memory types. Session Meta Memory is a default, system-managed store that automatically captures contextual data for the active session: session identifiers, user references, application context, and timestamps. It requires no configuration and gives agents immediate situational awareness from the moment a conversation begins.
Custom Memory Stores are persistent, user-defined stores that developers can read from and write to using code tools or workflow nodes. These stores are structured using JSON Schema, which enforces that only valid, properly formatted data is written to memory, making the knowledge base reliable and queryable at scale.
Granular Access Control Built for Enterprise
What gives this architecture its enterprise-grade depth is the access control model. Each Custom Memory Store is assigned one of three access types:
- User-specific - Data is scoped to individual users and persists across all their sessions, enabling genuine personalization over time.
- Application-wide - Data is available to every user across the entire application, suited for shared organizational knowledge such as policies or announcements.
- Session-level - Data is retained only for the duration of a single interaction, useful for capturing intermediate steps in multi-turn workflows without accumulating unnecessary long-term data.
Retention policies layer on top of these access types, allowing teams to set automatic data expiry at configurable intervals. This directly addresses both performance efficiency and compliance requirements.
Memory as a Multi-Agent Coordination Backbone
Across multi-agent workflows, this memory architecture functions as a coordination backbone. Specialized agents can read from and write to shared memory stores, passing structured context forward as a task moves between agents and systems, without requiring users to repeat information or lose continuity across handoffs.
For enterprises navigating regulatory obligations around data retention, access scope, and auditability, the combination of schema-enforced structure, granular access types, and configurable retention policies makes Kore.ai one of the most governance-ready agent memory platforms in the market today.
The compounding advantage of persistent AI agent memory
The business case for agent memory is not simply about making individual interactions better. It is about the compounding return on every interaction the agent has ever had.
An AI agent without memory delivers the same quality of output on its ten-thousandth interaction as on its first. It has learned nothing from the nine thousand nine hundred and ninety-nine interactions before. Every user experience is identical in its lack of personalization. Every workflow begins from zero.
An agent with well-designed persistent memory improves with use. Each interaction adds to its understanding of the user, the domain, and the organization. Preferences are refined. Edge cases are learned. Patterns are recognized. The agent becomes, over time, genuinely knowledgeable about the context it operates in, not because the underlying model improved, but because the memory system has accumulated and organized the experience of every interaction that came before.
This is not a marginal improvement. Research from Mem0 found that integrating persistent memory into LLM applications produces a 26 percent improvement in response quality. That is a significant performance uplift from an architectural addition rather than a model change. The implication is important: organizations that invest in AI agent memory infrastructure are not waiting for better models. They are extracting substantially more value from the models they already have.
The compounding dynamic also creates a durable competitive advantage. Memory stores built over months and years of real interaction are not replicable quickly. The institutional knowledge an AI agent accumulates about users, workflows, domain terminology, and organizational preferences represents a form of AI capital that appreciates with use and is genuinely difficult to replicate from a standing start.
Where AI Agent Memory Is Heading
Agent memory is moving quickly from an advanced capability to a baseline expectation. The major cloud providers have all announced or deployed managed memory services for their agentic AI platforms. Purpose-built agentic memory frameworks have emerged for organizations that need more control. The ecosystem is maturing at a pace that makes this year a meaningful inflection point.
The organizations that will lead in this next phase of AI adoption are not necessarily those with access to the most powerful models. They are the ones investing now in the infrastructure that makes those models durable: memory systems that turn one-off interactions into cumulative intelligence.
The question is not whether AI agent memory matters. It is whether your architecture is designed to take advantage of it.
FAQs
What is agent memory in AI?
Agent memory is the capability that allows an AI agent to retain, recall, and build on information across multiple interactions and sessions. Unlike stateless large language models that start fresh with every conversation, an AI agent with memory can store user preferences, interaction history, domain-specific facts, and behavioral rules, and retrieve that information to deliver more relevant, personalized responses over time.
What is the difference between short-term and long-term memory in AI agents?
Short-term memory in AI agents, also called working memory or in-context memory, refers to information available within the current session: the active conversation, the task at hand, and recent context. It is fast and immediately accessible but disappears when the session ends. Long-term memory for AI agents is stored persistently in external systems such as vector databases or knowledge graphs, survives across sessions, and must be retrieved on demand. Most enterprise AI deployments need both.
What are the types of AI agent memory?
The four main types of AI agent memory are: semantic memory (stored facts about users, domains, and preferences), episodic memory (records of past interactions and their outcomes), procedural memory (behavioral rules, protocols, and guidelines encoded into the agent), and working memory (the agent's active context window in the current session). Together, these four types enable an AI agent to behave in a way that is personalized, contextually aware, and consistent.
How is agent memory different from RAG?
Retrieval-Augmented Generation (RAG) is a read-only technique that gives an AI agent access to a static knowledge base at inference time. Every user draws from the same corpus and the knowledge base does not change based on interactions. Agent memory, by contrast, reads and writes. It is personal, evolves with every interaction, and is specific to each user or organization. RAG and agent memory are complementary: the best enterprise architectures use RAG for shared domain knowledge and persistent memory for user-specific context.
Why does agent memory matter for enterprises?
For enterprises, AI agents without persistent memory create serious operational gaps: users must repeat context in every session, agents cannot learn from experience, and complex multi-step workflows lose continuity across sessions. Agent memory addresses all three. It also creates a compounding advantage: every interaction adds to the agent's institutional knowledge, making it more accurate and useful over time. Research indicates that integrating persistent memory can improve AI agent response quality by 26 percent.
What are the biggest challenges in building AI agent memory?
The four main challenges are: staleness (stored facts become outdated as circumstances change), noise (memory stores degrade in retrieval quality as they grow without consolidation), governance (user data stored in memory is subject to GDPR, CCPA, and other privacy regulations), and multi-agent scoping (in enterprise deployments with multiple agents, defining what each agent can read and write requires careful architectural planning).






