












.webp)
When was the last time someone at your company asked not just whether your AI agents are running, but whether they're actually getting better?
Not "we upgraded the model." Better as in: you have evidence. A standard. A way to show exactly where the agent improved, why it improved, and what stopped that change from shipping until you were sure.
If that question stops you for a second, you're not behind. You're at the point most enterprise AI programs reach once the initial excitement wears off and the real work starts.
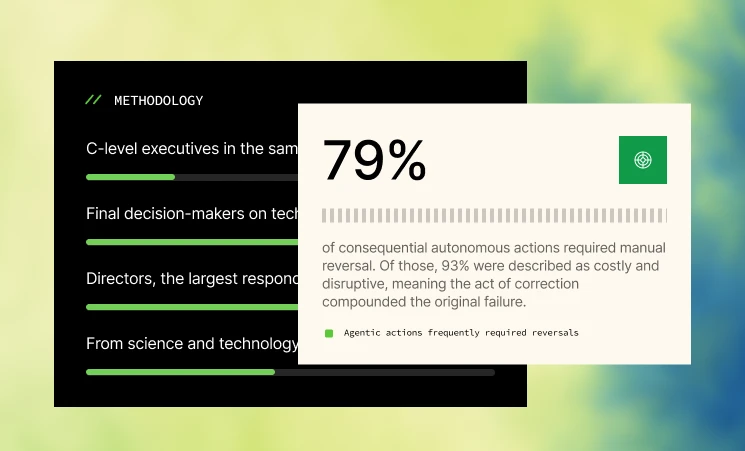
The numbers back this up. According to McKinsey's State of AI research, 88% of organizations now use AI in at least one business function, but only 39% report any measurable enterprise-level financial impact. Gartner predicts over 40% of agentic AI projects will be canceled by the end of 2027, largely due to escalating costs, unclear business value, or inadequate risk controls. Separately, Gartner predicts that by 2027, 40% of enterprises will demote or decommission autonomous AI agents because of governance gaps identified only after production incidents occur.
That last one is worth sitting with. Not before deployment. After production incidents.
The pattern: organizations find out what's broken only once something has already failed in front of a customer, a regulator, or an auditor. That's less a technology failure than a measurement failure, and it has a fix.
That fix has a name: an evaluation strategy. Without much fanfare, it's becoming the thing that separates enterprises building durable AI programs from the ones running very expensive pilots indefinitely.
Why standard AI benchmarks can't measure enterprise AI success
Every organization wants to know whether its AI agents are improving. Most don't have a consistent way to measure it, so they fall back on public benchmarks. Those benchmarks are genuinely useful for comparing the general capabilities of foundation models. That is what they were built for. They were never designed to measure enterprise success.
Every enterprise has its own goals, standards, policies, risk tolerance, customers, and definition of success. That success cannot be determined by a standard industry benchmark. Which is exactly why private evals matter: they turn your organization's definition of "good" into a measurable standard that every agent can be evaluated against, before and after deployment.
Public benchmarks measure generic capability. Your business does not run on generic capability. It runs on domain-specific judgment, policy-bound decisions, and outcomes that your customers can feel.
The gap between what a model scores on a leaderboard and what it actually delivers in your contact center, your back office, or your compliance workflow is where enterprise AI projects quietly fail. Not with a dramatic crash. Just a slow erosion of trust, a steady trickle of escalations, a creeping sense that the agent is unpredictable.
The fix is not a better model. The fix is knowing what good looks like for you, and having a system that measures against it continuously.
That is what a private eval is. And it is, genuinely, one of the most undervalued assets an enterprise can build right now.
What is a private evaluation and why does it matter for enterprise AI?
A private evaluation is a proprietary standard an enterprise builds to measure the quality, safety, and business performance of its own AI agents. Unlike a public benchmark, it is defined entirely by the organization's specific goals, policies, risk tolerance, and definition of a successful outcome, and it is used to continuously score every agent against that standard, both before and after deployment.
Think about what your best human agents, analysts, or service specialists actually know. They know when to push forward and when to pause. They know which policies apply in which situations. They know what a resolved outcome actually feels like versus a deferred one. That knowledge took years to accumulate. It lives in your SOPs, your training materials, your tribal knowledge, and frankly, in the instincts of your most experienced people.
Now imagine encoding that into a standard that your AI agents are continuously measured against. Not a generic rubric. Your rubric. Built from your domain, your risk appetite, your definition of a good customer outcome.
That standard, that private eval suite, is intellectual property in the truest sense. A competitor can access the same frontier model you use. They cannot access your definition of good. They cannot replicate the thousands of real interactions that shaped it. They cannot copy the refinements you have made based on what you learned in production.
This is where durable competitive advantage in the AI era actually lives. Not in which model you chose. In what you built around it.
The hidden risks of scaling AI agents without governance
That competitive advantage, the one built from your definition of good, only holds if the eval actually exists. Most enterprise AI teams don't have one. Instead, they build an agent, test it informally, deploy it, and monitor it loosely. When something goes wrong, they investigate. When a model gets deprecated, they scramble. When a regulator asks what guardrails were active on a given session, they dig through logs hoping the answer is somewhere in there.
This works at a small scale. It becomes a liability at any meaningful scale.
McKinsey's State of AI research puts this plainly: while 88% of organizations are using AI in at least one business function, only 39% report any measurable enterprise-level financial impact. The gap is not a technology gap. It is a governance and measurement gap.
At ten agents, informal quality checks are manageable. At fifty, governance gaps start to appear: policies diverge, teams reinvent the same guardrails independently, and audit requests take days instead of hours. At two hundred agents or more, you no longer have an AI program. You have a sprawl problem dressed up as an AI program.
Gartner describes this as the moment "agent sprawl becomes systemic risk." The architecture decision you make when you have twenty agents determines whether you can move fast and stay compliant when you have two hundred. That window to get it right is shorter than most teams think.
How a continuous AI evaluation loop works in practice
A mature eval architecture is not a one-time test suite. It is a living system: a defined standard, a continuous stream of production evidence measured against that standard, and a governed process for turning what you learn into improvements. Most teams have pieces of this. Very few have all three connected into a loop.
Here is what that looks like in practice, and why it matters so much more than most teams appreciate.
You start by defining what the agent is supposed to do: its goals, the policies it must follow, the guardrails it cannot cross, and the criteria that define a successful outcome. That definition is not a document sitting in a shared drive. It is a typed, executable specification, the kind you can diff, version, and review like code.
From that specification, you generate your eval suite before the agent ever touches production. You know what you expect it to do. You have asserted what it must never do. You have a baseline.
Then the agent runs. Every decision it makes, every tool call, every handoff it triggers, every guardrail event it hits: all of that becomes a trace. Those traces flow into your evals. The evals score the agent against your standard. The analysis surfaces where the agent is drifting, where knowledge gaps are causing failures, where a policy assertion is being missed.
And then, critically, that evidence becomes the input for the next improvement. Not a guess. Not a gut feel. A reviewable, evidence-backed proposal for what to change, gated by human approval before anything reaches production.
Every run makes the system smarter. Every improvement strengthens the artifact. The floor keeps rising. That is not a testing strategy. That is a compounding asset.
That compounding loop is also what makes one of the biggest recurring decisions in any AI program safer: choosing when, and whether, to switch models at all.
How private evaluation makes model switching risk-free
One of the biggest advantages of a private eval is that it makes model changes much less risky.
Model providers update pricing, deprecate versions, and release new capabilities regularly. For most organizations, deciding whether to switch is difficult because there's no objective way to measure whether the new model will perform better in their environment. The decision often comes down to limited testing and intuition.
A private eval changes that. Instead of treating a model migration as a leap of faith, enterprises can evaluate the new model against the same standards they've already established for their agents. They can compare quality, policy adherence, safety, and business outcomes before anything reaches production.
That makes model changes much less disruptive too. The model may change, but the standard against which it's measured does not, so every migration becomes a controlled experiment backed by evidence rather than assumptions.
That's what gives enterprises real control over their AI strategy: the model becomes a replaceable component, while the private eval remains the constant that protects quality, governance, and business outcomes.
Everything described so far (the defined standard, the continuous evidence loop, the governed model swaps) is exactly what Kore.ai built Artemis to operationalize.
How Kore.ai Artemis builds AI evaluation into the agent lifecycle
Most enterprises never build a private eval, and the ones that try often bolt it on after deployment, disconnected from how the agent was designed and separate from how it is governed in production. That is the exact problem Kore.ai built Artemis to solve. It is worth being specific about what that looks like in practice, because it goes considerably deeper than what most enterprise AI platforms offer on quality and evaluation.
- Evals begin at the blueprint, before a single line runs in production: Every agent in Artemis is authored using the Agent Blueprint Language (ABL), a typed, executable specification that makes the agent's goals, persona, rules, tool access, memory grants, guardrails, and success criteria fully explicit. From that blueprint, Arch, the platform's built-in AI architect, automatically generates a starter eval matrix covering persona, scenario, and evaluator coverage. You are not building tests after the fact. You are defining what good looks like as part of the design itself, before deployment.
- Evals cover correctness, safety, and policy simultaneously, in one harness: Artemis does not separate quality testing from compliance testing. Task accuracy, false escalation rate, PII handling, grounded answer policy, and compliance assertions are all evaluated in the same place, against the same standard. Resolution accuracy, containment rate, hallucination detection, knowledge gap identification, and context preservation across multi-turn conversations are all scored as a single unified quality picture. Your definition of good is holistic, not fragmented across tools and teams.
- Every production run becomes structured evidence: Once an agent is live, Artemis captures a reasoning-aware trace of every decision it makes: every tool call, every handoff, every guardrail event, every retrieval decision, every context handover, every approval gate. These are not logs you dig through manually when something goes wrong. They are structured, queryable, replayable records that feed directly into your eval suite. Decision records, tool call logs, context audit trails, guardrail events, quality signals, and drift monitoring are all visible, all scoreable, and all available the moment you need them.
- Coverage scales automatically as the agent evolves: Arch can draft new eval cases from the ABL, workflows, knowledge sources, and support documentation as the agent grows in scope. Your eval suite does not become stale when you add a new workflow or expand to a new channel. It grows with the agent, maintaining coverage across every dimension that matters to your business.
- Nothing ships if it drops a metric that matters: Artemis enforces regression gates across every release. A model swap, a prompt change, a workflow update, a knowledge base change: none of it can reach production if it degrades performance on your defined eval dimensions. The platform supports canary deployments and rollback so that promotion is always reversible. The bar you set is the bar that holds, across every release, for every team.
- The reinforcement loop runs continuously, with humans firmly in control: When Arch identifies a pattern in production traces, whether that is a drift signal, a knowledge gap, a guardrail outcome, or a latency spike, it does not just flag it. It proposes a reviewable patch: a specific, diff-able change to the ABL, the workflow, the prompt, the guardrails, or the eval suite itself. Engineers review it. They approve or reject it. The improvement is gated, versioned, and auditable. Every cycle raises the floor. Nothing improves without human sign-off.
- Quality is measured across every dimension your business cares about: The Artemis quality framework tracks faithfulness, knowledge coverage, safety, context preservation, hallucination rate, and customer intent signals, all in one dashboard. Agents are given a health status: healthy, warning, or critical. Quality regressions and knowledge gaps automatically feed the improvement backlog, creating a loop where every production signal becomes an input to the next optimization.
- One governance plane across every agent, inherited not reimplemented: Whether your agents are built natively in Artemis using ABL, authored visually in Studio, or connected externally via A2A or MCP protocols, they all run through the same governance surface. Identity, policy, audit trail, and eval gates are inherited automatically across every agent, every team, and every channel. SOC 2, ISO, and GDPR controls are structural, not bolted on. When a regulator asks what guardrails were active on a session from three weeks ago, the answer is available in seconds, not days.
The result is not just a platform with an eval feature. It is a platform where quality is the operating model: measurable, auditable, continuously compounding, and entirely owned by your business regardless of which model is running underneath it.
Why enterprise AI leaders should invest in private evals, not just better models
The model you use today will be replaced by a better one, probably within the year. Every enterprise using AI is already on that treadmill: evaluate, adopt, wait for the next release, repeat.
The evaluation you build today does not get replaced. It compounds. It gets richer with every production run, encodes deeper domain knowledge over time, and becomes harder for a competitor to replicate, not easier. That is the part of your AI program that actually behaves like an asset instead of an expense.
So the investment enterprise AI leaders should be making is not primarily in the next model. It is in the standard that outlives every model you will ever run: your definition of good, tested continuously, governed rigorously, and owned entirely by your business.
Start there. Build your standard. Own your private eval. Everything else, the model you choose, the vendor you pick, the architecture you scale, follows from that one decision.
FAQs
1. What is a private evaluation in enterprise AI?
A private evaluation is a proprietary standard an enterprise builds to measure the quality, safety, and business performance of its own AI agents. Unlike a public benchmark, it is defined entirely by the organization's specific goals, policies, risk tolerance, and definition of a successful outcome. It is used to continuously score every agent against that standard, both before and after deployment.
2. Why can't standard AI benchmarks measure enterprise success?
Standard AI benchmarks are built to compare the general capabilities of foundation models, not to measure enterprise outcomes. Every enterprise has its own goals, policies, risk tolerance, and definition of success, none of which a generic industry benchmark accounts for. A model can score well on a public leaderboard and still perform unpredictably in a specific contact center, back office, or compliance workflow.
3. What happens if enterprises scale AI agents without governance?
At a small scale, informal quality checks and loose monitoring are manageable. Past roughly fifty agents, governance gaps start to appear: policies diverge, teams rebuild the same guardrails independently, and audit requests take days instead of hours. At two hundred agents or more, the result isn't an AI program anymore, it's a sprawl problem. Gartner describes this tipping point as the moment agent sprawl becomes systemic risk.
4. How does a private eval make switching AI models safer?
A private eval turns a model migration from a leap of faith into a governed experiment. Instead of relying on limited testing and intuition, enterprises can run a candidate model against the same standards already established for their agents, comparing quality, policy adherence, safety, and business outcomes before anything reaches production. The model becomes replaceable; the eval stays constant.
5. How does Kore.ai Artemis build evaluation into the AI agent lifecycle?
Artemis generates a starter eval matrix directly from an agent's Agent Blueprint Language (ABL) specification, before the agent ever reaches production. Every production run then becomes a structured, queryable trace that feeds back into the eval suite. Regression gates block any release that degrades a defined metric, and Arch proposes reviewable improvements that require human approval before shipping. Quality, safety, and policy are evaluated together in one harness rather than as separate tools.






