












.webp)
FIT-RAG: Are RAG Architectures Settling On A Standardised Approach?
As RAG is being used, vulnerabilities are emerging & solutions to these problems are starting to look very much alike.
Introduction
It is interesting to see that as technology advance, most everyone converges on what is deemed as a good design.
Taking for example prompt engineering, prompts evolved into templates with placeholders where variables could be injected.
This evolved into prompt chaining, and eventually autonomous agents which have multiple tools at its disposal.
Hence RAG is going through very much the same trajectory…initially RAG as such was deemed sufficient. However, now additional intelligence is being added to the RAG stack, together with a number of other elements forming part of the RAG architecture.
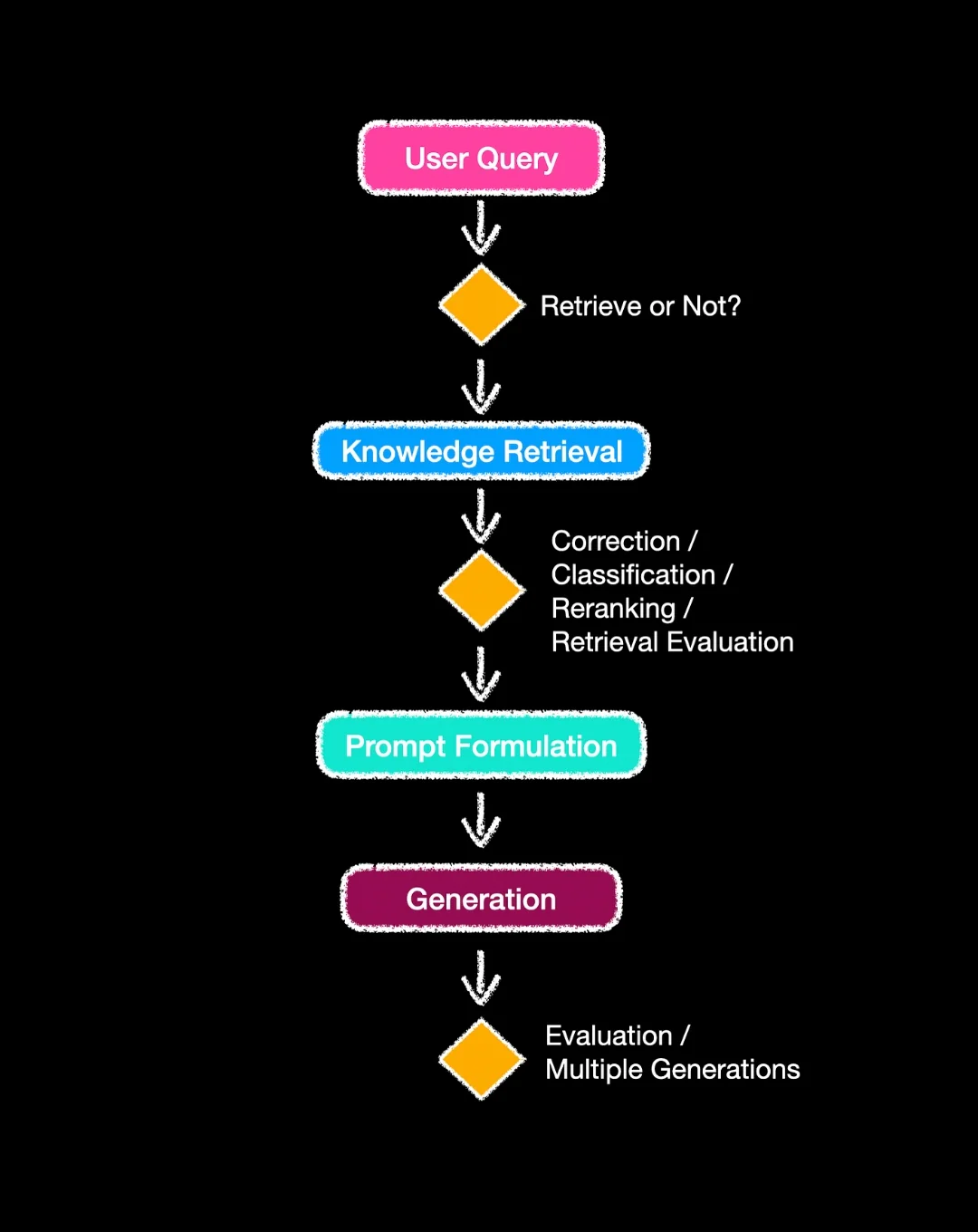
Four initial considerations
Firstly, as you will see in the article below, the prompt structure is becoming increasingly important in RAG architectures, and prompting techniques like Chain-of-Thought, amongst others are being introduced.
Merely injecting the prompt with contextual reference data is not enough anymore, and prompt wording is being leveraged to optimise the performance.
Secondly, it is being recognised that RAG is static in two regards. The first element is that RAG does not necessarily take into consideration the context of the conversation, or at least consider the context spanning over a number of dialog turns.
Added to this, the decision to retrieve or not, is often based on a set of static rules, which lacks flexibility.
Thirdly, unnecessary overhead is becoming a consideration, with unneeded and un-optimised retrievals, additional text adding unwanted cost and inference latency.
Fourthly, multi-step approaches and classifiers are used to decide on the best response to select. Or to make use of multiple data stores or merely classify the user request. These classifiers are often dependant on annotated data which is used to train a model for this specialised task.

CRAG, is a lightweight retrieval evaluator which assesses the overall quality of retrieved documents, providing a confidence degree to trigger different knowledge retrieval actions.
And as I have stated before, RAG is moving towards a state which LlamaIndex refers to as Agentic RAG. Where a RAG based agent is used to manage the retrieval of data making use of multiple sub-agents or tools.
FIT-RAG
The FIT-RAG study identifies two problems considering LLMs and factual data…
Lack of Factual Data: The desired documents in LLMs might lack the necessary factual information for the specific query, potentially leading the retriever astray and undermining the effectiveness of black-box RAG.
Token Overload: Merging all retrieved documents indiscriminately results in an excess of tokens used for LLMs, diminishing the efficiency of black-box RAG.
FIT-RAG leverages factual information by devising a bi-label document scorer. This scorer incorporates factual information and LLM preferences as distinct labels.
Additionally, FIT-RAG implements token reduction strategies, including a self-knowledge recogniser and a sub-document-level token reducer. These innovations aim to minimise unnecessary augmentation and significantly decrease augmentation tokens, enhancing FIT-RAG’s efficiency.
Out-of-date and long-tail knowledge lead to LLMs struggling with hallucinations and factual errors, especially in knowledge-intensive tasks.
~ Source
Components of FIT-RAG
Considering the image below, FIT-RAG comprises of five integral components:
- A similarity-based retriever,
- A bi-label document scorer,
- Bi-faceted self-knowledge recogniser,
- Sub-document-level token reducer, and
- Prompt construction module.
Notably, the bi-label document scorer is designed to adeptly capture alignment with both LLM preferences and factual information, mitigating the risk of factual ignorance.
Moreover, the bi-faceted self-knowledge recogniser and sub-document-level token reducer play pivotal roles in minimising input tokens, thus averting token wastage.

The bi-label document scorer is trained using bi-label learning, which involves two labels:
- Factual information (Has_Answer) and
- LLM preference (LLM_Prefer).
The Has_Answer label indicates if the document contains the answer to the question, while LLM_Prefer indicates if the document helps the LLM generate an accurate response.
However, there’s a significant data imbalance between these labels, which can impact the performance of bi-label learning. To address this, the paper proposes a data-imbalance-aware bi-label learning method.
This method assigns different weights to the data, which are automatically learned using hyper-gradient descent. This approach effectively tackles the data imbalance issue, enabling the bi-label document scorer to provide a comprehensive evaluation of retrieved documents.
The bi-faceted self-knowledge recogniser assesses whether the LLM necessitates external knowledge by evaluating two facets: whether the question pertains to long-tail or outdated information, and whether the question’s closest counterparts possess self-knowledge.
Meanwhile, the sub-document-level token reducer removes redundant sub-documents by choosing combinations from the retrieved documents with fewer sub-documents but still capable of enhancing the LLM’s ability to provide accurate answers.
FIT-RAG prompting
The image below shows how the prompt wording is optimised…

Conclusion
Integrating agentic capabilities into your RAG (Retriever-Reader-Generator)pipeline can significantly enhance its capacity to tackle intricate queries and reasoning tasks. By augmenting your pipeline with agentic capabilities, you empower it to handle a broader range of complex questions and scenarios.
However, one significant challenge faced by agents is the inherent lack of steerability and transparency in their decision-making processes. When confronted with a user query, an agent may resort to a chain-of-thought or planning approach, necessitating repeated interactions with large language models (LLMs) to navigate through the problem space effectively.
This reliance on iterative interactions with LLMs not only introduces computational overhead but also impedes the agent’s ability to provide transparent explanations for its decisions.
Consequently, there arises a pressing need to develop mechanisms that enhance the steerability and transparency of agentic systems, enabling users to better understand and influence their behaviour.
Addressing these pain points would not only improve the efficiency and effectiveness of agentic systems but also foster greater trust and collaboration between humans and AI agents in tackling complex tasks and problem-solving scenarios.
Read the full study here.





