












.webp)
I have thoroughly examined some of the recent academic papers on RAG (Retrieval-Augmented Generation) and have identified several common challenges raised in studies associated with implementing retrieval-augmented solutions.
- Six General Shortcomings
- Seven Potential Failure Points
- The Challenge Of Accurate
- Assessment Of User Queries,
- Accurate Retrieval & Data Privacy.
Introduction
RAG (Retrieval-Augmented Generation) has gained significant popularity in developing Generative AI applications.
There are four key reasons behind the widespread adoption of RAG in this domain:
1. Leveraging the Power of In-Context Learning (ICL): RAG capitalises on one of the most potent features of Large Language Models (LLMs), namely In-Context Learning. When provided with contextual references, LLMs prioritise contextual data over the base-model training data. This approach is particularly effective in mitigating issues like hallucination.
2. Non-Gradient Approach: Unlike gradient-based methods, RAG offers a non-gradient approach. This enables customisation of Generative AI solutions without the need for fine-tuning individual LLMs. Consequently, a degree of independence from specific LLMs can be attained.
3. Enhanced Observability & Inspectability: Fine-tuning a base model often lacks transparency, resulting in limited observability and inspectability during both the fine-tuning process and in production. In contrast, RAG provides a higher level of observability and inspectability as it is not as opaque as adjusting the base model. Questions or user inputs can be compared with retrieved chunks of contextual data, which can then be contrasted with the responses generated by LLMs.
4. Simplified Maintenance: Continuous maintenance of a RAG solution is more manageable due to its compatibility with a less technical and incremental approach. This makes it easier to address evolving needs and challenges over time.
Traditional RAG shortcomings
A number of shortcomings of traditional RAG were highlighted in another study:
- The strategies used for deciding when to make use of RAG as apposed to other methods often rely on a set of static rules. The conversational UI usually has a number of parameters which triggers a call to the RAG implementation.
- The strategies for deciding what to retrieve typically limit themselves to the LLM’s most recent sentence or the last few tokens.
- With the lookup trigger not being optimised, unnecessary retrievals take place.
- These unnecessary and un-optimised retrievals can add unwanted noise, where the retrieved data is not optimised.
- The overhead in text adds additional cost and inference wait time, potentially timeouts.
- RAG does not necessarily maintain and take into consideration the complete contextual span of the conversation.
Successful assessment of user queries
The challenge inherent in any Large Language Model (LLM) implementation lies in effectively recognising simple user queries without introducing unnecessary computational overhead, while also ensuring the adequate handling of more complex multi-step queries.
However, there exists a spectrum of queries that fall between these extremes, necessitating a nuanced approach.
To address this challenge, a recent study presented an adaptive Question-Answering (QA) framework. This framework is tailored to select the most suitable strategy for Large Language Models (LLMs), including retrieval-augmented models, based on the complexity of the query.
By dynamically adjusting the approach from simple to complex as needed, this framework aims to optimise performance across a range of query types.
Considering the graph below, it is evident that there needs to be a balance between query time, quality in terms of performance, but also efficiency. With cost also being a consideration.
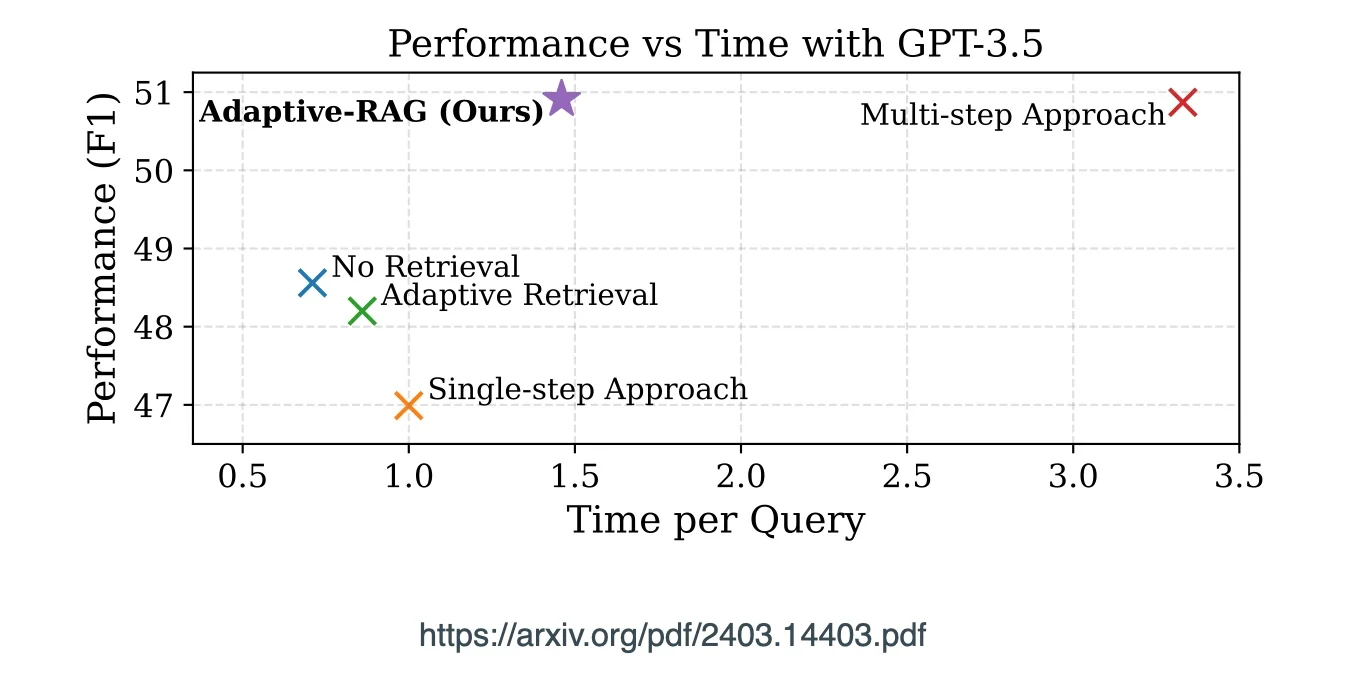
RAG implementations are becoming increasingly complex with classifiers and agent-like implementations.
Accurate retrieval
In recent studies there have been efforts to reduce the noise introduced at inference. This is where information is retrieved which is not relevant to the current context.
Frameworks like RAFT, when presented with a question and a batch of retrieved documents, instructs the model to disregard those documents that do not contribute to answering the question. These disregarded documents are referred to as distractor documents.
Added to this, optimising the size of the context injected is also important in terms of token usage costs, timeout and payload overheads.
Data privacy
Another study has shown RAG systems are highly susceptible to attacks, with a considerable amount of sensitive retrieval data being extracted.
The study shows that in some instances omitted the {command} component and utilised direct prompting phrases like My phone number is and Please email me at to access the private data in pre-training/fine-tuning datasets of LLMs.
Seven potential RAG failure points
Missing content
Failure can occur while posing a question that cannot be addressed using the existing documents. In the favourable scenario, the RAG system will simply reply with a message such as “Sorry, I don’t know.” However, in cases where questions are relevant to the content but lack specific answers, the system might be misled into providing a response.
Missed top ranked
The document contains the answer to the question but didn’t rank high enough to be presented to the user. In theory, all documents are ranked and considered for further processing. However, in practice, only the top K documents are returned, where the value of K is chosen based on performance metrics.
Not in context
Documents containing the answer are successfully retrieved from the database but are not included in the context used to generate a response.
This situation arises when multiple documents are retrieved from the database, and a consolidation process is employed to extract the answer.
Wrong format
The question required extracting information in a specific format, such as a table or list, yet the large language model disregarded this instruction.
Incorrect specificity
The response includes an answer, but it lacks the required specificity or is overly specific, failing to meet the user’s needs.
This situation arises when the designers of the Retrieval-Augmented Generation (RAG) system have a predetermined outcome for a given question, such as providing educational content for students.
In such cases, the response should include not only the answer but also specific educational materials. Incorrect specificity can also occur when users are uncertain about how to phrase a question and provide overly general queries.
Not extracted
In this scenario, the answer is within the context provided, but the large language model fails to accurately extract it. This usually happens when there is excessive noise or conflicting information within the context.
Incomplete answers
Incomplete answers are not necessarily incorrect but lack some information, even though it was present in the context and could have been extracted.
For instance, consider a question like “What are the key points covered in documents A, B, and C?” A more effective approach would be to ask these questions separately for each document to ensure comprehensive coverage.
I need to mention that this scenario is solved for by an approach from LlamaIndex called Agentic RAG. Agentic RAG allows for a lower level agent tool per document, with a higher order agent orchestrating the agent tools.





