












.webp)
Enterprises have always operated within increasingly complex information ecosystems, where critical knowledge spans legacy repositories, cloud platforms, line-of-business tools, and vast volumes of unstructured content. Gartner reports that 80% of organizations struggle with fragmented data, and McKinsey reports employees lose 20% of their time searching for information. With 70% lacking effective metadata practices and 60% facing challenges balancing access, security, and compliance, traditional search pipelines, whether keyword, semantic, or vector-based, frequently deliver incomplete or poorly contextualized results. These limitations become especially visible when queries require multi-step reasoning, cross-system interpretation, or synthesizing insights across disparate sources.
This is precisely where Agentic RAG provides a meaningful architectural advantage. Rather than functioning as a static retrieve-and-respond pipeline, Agentic RAG introduces an intelligent orchestration layer capable of interpreting intent, planning reasoning steps, adapting retrieval strategies, and refining context dynamically. It strengthens existing enterprise AI systems without forcing teams to rearchitect their data platforms, enabling more accurate, explainable, and context-aware outputs that align with enterprise workflows and compliance requirements. In this blog, we examine how Agentic RAG works, why it directly addresses long-standing enterprise search and knowledge challenges, and where it delivers the greatest impact across mission-critical, real-world use cases.
What is agentic RAG?
Agentic Retrieval-Augmented Generation, or Agentic RAG, represents the current state of the art in applied AI architecture. It extends the traditional RAG model by adding an intelligent, agent-driven control layer that can reason about tasks, determine what information it needs, and actively shape the context used during generation. Instead of behaving like a static pipeline that retrieves some documents and feeds them into a model, Agentic RAG operates more like a coordinated reasoning system, one that can plan, adapt, validate, and refine its own steps in real time. This makes it exceptionally well-suited for enterprise environments where accuracy, traceability, and contextual awareness are non-negotiable.
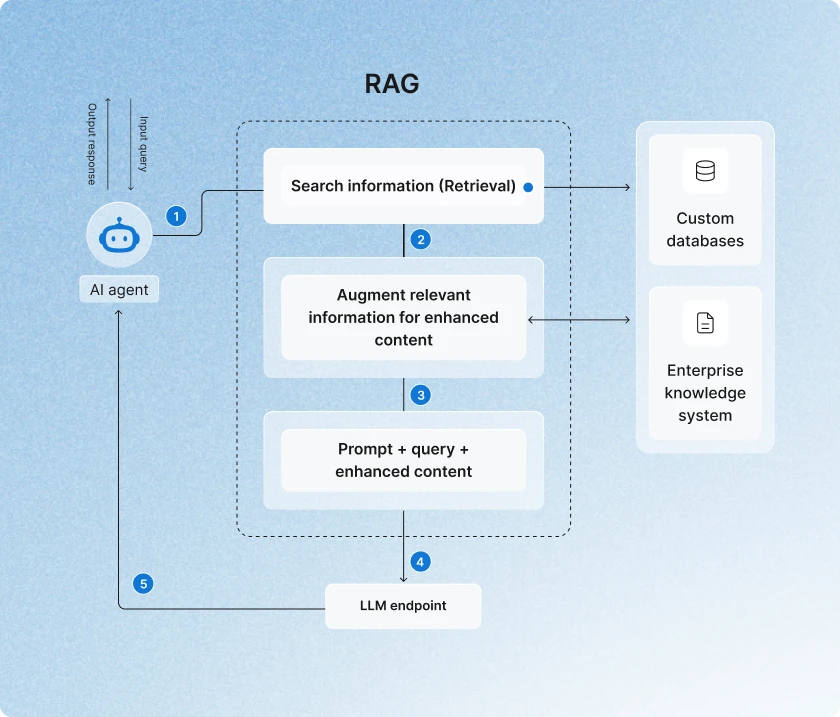
At the center of the architecture is the A-R-A-G pattern, Agentic, Retrieval, Augmentation, and Generation, a sequence that captures how the system thinks, gathers evidence, transforms that evidence, and ultimately produces a grounded output. Each component plays a distinct role but works together as a tightly integrated process.
- Agentic (A) is the intelligence that drives everything. This layer interprets the user’s goal, plans the reasoning steps, chooses retrieval strategies, and decides when context needs to be refined. It is capable of re-evaluating its own decisions, iterating through multiple cycles, and adapting the workflow based on the evolving state of the task. In practical terms, this is what allows Agentic RAG to behave like an autonomous system rather than a simple query-response mechanism.
- Retrieval (R) supplies the system with high-value, domain-specific information by pulling from vector stores, search indices, structured data repositories, and long-form content. Retrieval in Agentic RAG is not a one-shot operation. The agent interprets the task, formulates or reformulates queries, adjusts search parameters, and runs multi-hop retrieval when deeper context is needed. This ensures the system gathers not just relevant information, but the right information for the problem it is solving.
- Augmentation (A) is where retrieved material is transformed into a usable reasoning context. Rather than passing raw documents to the model, the system restructures, filters, summarizes, enriches, and aligns the information to match the requirements of the task. The agent evaluates this augmented context, checks for completeness, and triggers additional retrieval when needed. This is the stage where Agentic RAG differentiates itself most clearly from earlier RAG designs, because augmentation becomes an active, intelligent process rather than a passive formatting step.
- Generation (G) is the final stage, where a large language model synthesizes the curated context into a coherent output. Because the input has been actively retrieved and shaped under the agent’s supervision, the generative step produces responses that are far more accurate, grounded, and compliant with domain constraints. The agent continues to monitor this stage by validating the output, checking for inconsistencies, and iterating when corrections are required.
Together, these four components form a modular, high-performance architecture capable of powering multi-step reasoning, domain-specific co-pilots, workflow agents, and complex decision-support systems. Agentic RAG is already deployed across industries such as healthcare, finance, legal operations, and enterprise knowledge management, demonstrating its maturity, reliability, and practical value.
As a result, Agentic RAG has become the new foundational standard for building intelligent, context-driven AI systems, one that enables organizations to move beyond simple automation toward adaptive, reasoning-capable AI that can operate confidently in real-world environments. It is this combination of autonomy, contextual awareness, and architectural flexibility that positions Agentic RAG at the center of the next generation of enterprise AI.
Benefits of agentic RAG over traditional RAG
The shift from traditional Retrieval-Augmented Generation (RAG) to Agentic RAG represents one of the most important advancements in modern AI architecture. Traditional RAG was designed primarily as a mechanism for improving language model responses by grounding them in retrieved information. It executed a simple two-step pipeline: retrieve documents, then generate text based on those documents. While effective in many scenarios, the model had limited awareness of task complexity, could not adapt its workflow, and lacked the ability to reason about what information it actually needed.
Agentic RAG changes this entirely. By introducing agentic behavior, planning, decision-making, iterative refinement, and adaptive retrieval, it elevates the architecture from a static helper to a dynamic reasoning system. Instead of passively responding to retrieved content, Agentic RAG actively decides what to retrieve, how to refine it, when to re-query, and how to structure its reasoning path. This results in far more accurate, context-aware, and reliable outcomes, especially for enterprise environments where tasks require multi-step reasoning and precise interpretation.
The evolution reflects a broader industry shift: organizations now expect AI systems to perform with autonomy, contextual intelligence, and operational consistency. Domains such as healthcare, financial services, customer support, and research rely heavily on systems that can interpret complex information and adjust their behavior in real time. Agentic RAG delivers this capability by behaving less like a static pipeline and more like an intelligent collaborator.
Traditional RAG vs agentic RAG:
Below is a detailed comparison highlighting how Agentic RAG expands the capabilities of traditional RAG:
The shift from traditional RAG to Agentic RAG is not just a technical upgrade; it is a strategic advancement for organizations seeking trustworthy, context-aware AI. Traditional RAG improved response quality, but it lacked the reasoning depth required for enterprise-scale tasks. Agentic RAG addresses this gap by enabling AI systems that understand context, adapt their behavior, refine their reasoning, and deliver outputs aligned with business logic and domain expectations.
Enterprises deploying Agentic RAG benefit from improved decision support, more reliable workflow automation, deeper contextual grounding, and stronger alignment with operational realities. It empowers teams to offload complex analytical tasks to AI systems that act with human-like reasoning discipline and consistency. As organizations continue to scale their AI initiatives, Agentic RAG provides a foundation that supports long-term accuracy, efficiency, and intelligent automation across the entire enterprise.
Core concepts of agentic RAG
Agentic RAG is built on a set of foundational concepts that transform a traditional retrieval-augmented system into a fully adaptive, reasoning-driven architecture. These concepts define how the system interprets tasks, plans its workflow, retrieves information, constructs context, and validates its outputs. Together, they form the operational intelligence that makes Agentic RAG significantly more powerful and reliable than conventional RAG models.
At its core, Agentic RAG functions not as a fixed pipeline but as an orchestrated reasoning system. It determines what information is needed, how to obtain it, how to refine it, and how to use it to generate high-quality outputs. This shift from static execution to adaptive decision-making is what enables Agentic RAG to perform well in complex enterprise environments where context changes rapidly and tasks require multi-step reasoning. Below are the key technical concepts that define how Agentic RAG works.
1. Agentic control logic
The defining concept of Agentic RAG is the introduction of an autonomous control layer, a planner or orchestrator, responsible for driving the entire reasoning process.
This agent does more than route data; it interprets the user’s objective, breaks it into actionable steps, and decides which tools or retrieval strategies to invoke.
Key roles of the agentic controller include:
- Assessing whether current information is sufficient
- Initiating additional retrieval cycles when gaps are detected
- Selecting between long-context reasoning, multi-hop search, or targeted retrieval
- Directing how context is structured before generation
- Triggering validation or refinement when inconsistencies appear
This control logic allows Agentic RAG to behave like a decision-making system rather than a one-pass pipeline.
2. Iterative and adaptive retrieval
In Agentic RAG, retrieval is not a single query; it is an iterative and adaptive process guided by the agent.
The system continuously evaluates whether retrieved information meets the task requirements and adjusts its retrieval strategy accordingly.
Core retrieval concepts include:
- Dynamic query rewriting based on partial evidence
- Multi-hop retrieval, where one retrieved result triggers another
- Cross-source retrieval, combining vector search, keyword search, structured data, and domain-specific repositories
- Confidence scoring and filtering to remove irrelevant or low-value items
This iterative retrieval loop ensures that the system accumulates the most relevant, complete, and high-precision evidence before building context.
3. Context augmentation and structuring
A hallmark of Agentic RAG is that raw retrieval outputs are never passed directly to the language model.
Instead, the agent orchestrates a context augmentation layer that transforms retrieved data into a clean, structured, and task-aligned context package.
Key augmentation concepts include:
- Semantic ranking and pruning to eliminate noise
- Context synthesis to merge multiple information sources into a coherent knowledge block
- Chunk restructuring to optimize context window usage
- Domain-aware filtering to surface information relevant to enterprise logic
- Memory integration, where past interactions influence context formation
This ensures the generation model receives the best possible information foundation.
4. Multi-step reasoning and validation
Agentic RAG incorporates validation loops and multi-step reasoning pathways, enabling the system to check its own work before finalizing an output.
Core reasoning concepts include:
- Intermediate reasoning evaluation to detect contradictions or missing data
- Self-correction cycles that automatically refine the output by returning to retrieval or augmentation
- Rule-based or model-based validation to enforce enterprise guidelines, compliance rules, or factual integrity
- Recursive generation, where the model iteratively improves responses through agent-driven prompts
This makes Agentic RAG substantially more reliable than traditional RAG in high-risk or knowledge-heavy environments.
5. Autonomous workflow adaptation
Unlike static RAG pipelines, Agentic RAG adapts its workflow dynamically as the task progresses.
The agent monitors context, identifies shifts in user intent, and adjusts its strategy accordingly.
Examples of workflow adaptation include:
- Shifting from shallow retrieval to deep multi-hop search
- Switching from extractive context building to structured summarization
- Choosing between strict fact-generation or exploratory reasoning
- Altering the reasoning path when new evidence contradicts prior information
This flexibility allows Agentic RAG to function effectively in fast-changing enterprise scenarios such as diagnostics, compliance checks, research support, and knowledge-intensive automation.
How agentic RAG works:
Agentic RAG operates through a tightly orchestrated sequence of reasoning and retrieval steps that begin the moment a user submits a question. Unlike traditional RAG, which performs a single retrieval followed by generation, Agentic RAG uses autonomous AI agents to interpret the query, plan the workflow, retrieve information iteratively, refine context, validate results, and ensure the final answer is grounded, accurate, and enterprise-ready.

1. Understanding the user query
The process starts when a user provides a question or instruction. The AI agent evaluates the intent behind the request, determines the complexity of the task, and identifies whether it requires a straightforward factual response or a multi-step reasoning operation. This initial interpretation shapes how the system proceeds and ensures that the query is fully understood before any retrieval begins.
2. Agentic planning and workflow design
Once the query is understood, the agent plans the reasoning pathway. This involves deciding which enterprise data sources must be consulted, whether the query should be decomposed into smaller tasks, and what sequence of operations will produce the most accurate outcome. The agent determines whether the workflow requires knowledge graph traversal, hybrid search, tool invocation, or iterative retrieval. This planning stage introduces intelligence and orchestration into the RAG pipeline.
3. Iterative retrieval across enterprise knowledge sources
The system then initiates retrieval. But instead of a single search, Agentic RAG executes multiple retrieval cycles across vector databases, keyword indexes, structured systems, APIs, and knowledge graphs. Retrieval agents refine their searches based on the evolving context. If the initial results are incomplete or irrelevant, the agent rewrites the query, adjusts search strategies, or performs multi-hop retrieval to locate deeper contextual information. This iterative approach ensures comprehensive and relevant evidence collection.
4. Augmentation and context preparation
After retrieval, the system transforms raw evidence into a structured, context-rich representation. The augmentation layer cleans, summarizes, reorganizes, and enriches the retrieved content so it can be effectively consumed by the LLM. Redundant text is removed, key insights are highlighted, conflicting information is resolved, and the final context window is optimized for reasoning. This stage ensures the model receives only the most relevant, high-value knowledge.
5. Prompt construction
With the curated evidence ready, the system constructs the final prompt to guide the model. This prompt blends the user’s request, the augmented context, enterprise constraints, and any formatting or reasoning requirements. The design of this prompt ensures that the generative model remains grounded in authentic data, follows organizational rules, and produces answers aligned with the intended purpose.
6. Controlled and grounded response generation
The LLM then generates the response, synthesizing the structured evidence into a coherent, contextually accurate output. Because the system’s agentic layer constrains reasoning, the model does not hallucinate or invent unsupported information. Instead, generation is tightly aligned with the provided evidence and adheres to domain-specific expectations. The result is a well-reasoned, enterprise-grade answer.
7. Validation and quality assurance
Before the answer is delivered, the system runs validation checks. The agent compares the generated response against retrieved evidence, ensuring accuracy, completeness, and logical coherence. It evaluates compliance with business rules and verifies that the answer resolves the user’s intent. If any inconsistencies or gaps are detected, the system moves into refinement rather than returning a flawed result.
8. Refinement and re-execution of retrieval
If validation identifies issues, the agent triggers a refinement loop. This may involve retrieving additional evidence, restructuring context, adjusting the prompt, or regenerating parts of the answer. Refinement continues until the system produces a complete, correct, and contextually aligned response that meets enterprise quality standards.
9. Delivery of the final answer
Once fully validated, the final answer is delivered to the user. The response is grounded in verified information, tailored to the query, consistent with enterprise knowledge sources, and ready for immediate operational use. It reflects the full intelligence of the agentic workflow and provides transparent, trustworthy insights.
10. Logging, observability, and continuous improvement
Behind the scenes, every action taken by the agent, retrieval decisions, reasoning steps, validation checks, and generation outputs, is logged for observability and governance. This enables enterprises to audit AI behavior, diagnose errors, refine retrieval pipelines, and continuously improve model performance. Over time, the system becomes faster, more accurate, and more aligned with real-world usage patterns.
Agentic RAG works by combining structured planning, iterative retrieval, intelligent augmentation, guided generation, and rigorous validation into a single continuous reasoning cycle. This enables organizations to move beyond simple search or static automation and into a new era of AI that is adaptive, transparent, and capable of supporting complex enterprise workflows with precision.
Key capabilities of agentic RAG:
Agentic RAG, or Agentic Retrieval-Augmented Generation, introduces advanced capabilities that significantly improve how enterprise AI systems retrieve, process, and generate information. These capabilities transform traditional RAG models into adaptive, context-aware reasoning systems that deliver higher accuracy, reliability, and operational value. The following sections break down the core features that make Agentic RAG a powerful architecture for modern enterprise AI applications.
1. Enhanced retrieval for high-accuracy enterprise AI
One of the foundational strengths of Agentic RAG is its enhanced retrieval capability. Unlike static RAG pipelines, Agentic RAG uses intelligent retrieval strategies that continuously adapt based on the task and the available data. This ensures that enterprise AI systems operate with the most relevant, validated, and up-to-date information.
Key enhancements in retrieval include:
- Dynamic query optimization that rewrites and adjusts retrieval queries in real time.
- Multi-hop and iterative retrieval that gathers evidence step by step to support deeper reasoning.
- Automated relevance validation that ensures retrieved results match the context and intent of the task.
This capability is essential for enterprises needing accurate, evidence-backed AI outputs across knowledge management, customer support, legal research, and complex analytical workflows.
2. Augmentation and generative processing for context-rich outputs
The augmentation layer is a defining element of Agentic RAG and a major value driver for organizations implementing advanced RAG architectures. This layer transforms raw retrieved data into a structured, enriched, and optimized context before generation. It directly improves the quality, precision, and domain alignment of AI outputs.
Core augmentation and generative capabilities include:
- Context restructuring and summarization to turn raw search results into usable knowledge artifacts.
- Semantic filtering and enrichment to improve clarity, remove noise, and add helpful context.
- Optimized context packaging to ensure the generative model works with clean, relevant input.
- Fact-grounded synthesis where outputs are generated based on validated, augmented evidence.
By pairing augmentation with controlled generation, enterprise AI systems powered by Agentic RAG deliver responses that are more accurate, compliant, and actionable.
3. Adaptive and context-aware responses for real-time enterprise needs
Agentic RAG stands out for its ability to adapt its reasoning based on real-time context, making it ideal for enterprise environments that require reliable and scalable AI systems. This adaptiveness elevates the framework beyond traditional RAG approaches.
Key aspects of adaptive response capability include:
- Continuous evaluation of reasoning steps to detect gaps, inconsistencies, or missing information.
- Autonomous refinement loops that trigger additional retrieval or augmentation when needed.
- Context-driven workflow adjustments ensuring that each reasoning step aligns with the evolving task.
This adaptive behavior is crucial for enterprise AI implementations where accuracy and contextual precision directly influence business outcomes.
These capabilities make Agentic RAG one of the most effective architectures for implementing reliable, context-aware enterprise AI systems. By integrating advanced retrieval, intelligent augmentation, and controlled generation, the framework enables AI systems that perform more like skilled knowledge workers and less like static automation tools. Enterprise teams can leverage Agentic RAG to improve decision support, automate complex workflows, reduce manual research time, and enhance customer-facing AI with better accuracy and contextual grounding.
As organizations continue to scale their AI deployments, Agentic RAG provides a future-ready architecture that supports long-term growth, operational efficiency, and higher-quality outcomes. It is the bridge between simple autogenerated responses and the sophisticated, context-rich reasoning required in modern enterprise environments.
Agentic AI application and use-cases
Agentic RAG systems are especially useful in enterprise environments where knowledge is fragmented across systems. Common applications include:
1. Multi-system enterprise knowledge retrieval
Agentic RAG unifies knowledge scattered across CRMs, wikis, document repositories, ticketing systems, data warehouses, and legacy tools. By performing multi-hop retrieval and query reformulation, it produces coherent, context-rich answers that would normally require manually stitching together information from several systems.
2. Complex document interpretation and policy reasoning
In domains like legal, HR, risk, and compliance, Agentic RAG can read long-form documents, extract obligations, interpret clauses, resolve contradictions, and align insights with internal policies. Its augmentation layer performs semantic restructuring and relevance filtering, allowing the system to reason over dense content with high fidelity.
3. Procedural and diagnostic troubleshooting
Engineering, IT support, and operations teams benefit from Agentic RAG’s ability to reason through step-by-step procedures. The system can decompose a problem, retrieve configuration data, compare logs or known issues, and produce guided troubleshooting paths using multi-step reasoning and iterative context refinement.
4. Research and multi-dataset synthesis
Product, strategy, and R&D teams often work with heterogeneous data sources, market research, analytics dashboards, customer feedback, technical specs. Agentic RAG pulls evidence from all these repositories, performs cross-source correlation, and generates synthesized insights or recommendations backed by retrieved data.
5. Personalized enterprise search and role-aware context delivery
Because Agentic RAG considers user permissions, departmental context, and historical activity, it delivers responses tailored to an individual's environment. This is particularly valuable in large enterprises where roles, access levels, and domain needs vary widely. The agentic layer ensures retrieval depth matches each user’s operational responsibilities.
6. Regulated-industry decision support
Industries like healthcare, banking, insurance, and pharmaceuticals need reliable, traceable AI. Agentic RAG can source evidence from approved repositories, validate data against domain rules, and produce compliant, audit-ready responses. Iterative retrieval and validation loops reduce hallucination risk to acceptable regulated thresholds.
7. Real-time contextual support in customer-facing workflows
In customer service, Agentic RAG retrieves knowledge articles, product documentation, diagnostic procedures, and past cases to generate accurate, context-specific responses. The system can refine retrieval when data is missing and validate generated answers against known internal knowledge sources before they reach a customer.
Kore.ai agentic RAG in Kore.ai - search and data AI
Kore.ai places Agentic RAG at the core of its Search and Data AI architecture, enabling the platform to autonomously interpret user intent, orchestrate retrieval across distributed enterprise data sources, and construct grounded, verifiable answers. The system combines a large-scale ingestion and enrichment pipeline with multi-vector indexing, AI-driven knowledge graphs, and rigorous governance to deliver context-aware, evidence-backed responses at enterprise scale. Agentic RAG functions as the reasoning layer, coordinating extraction, retrieval, augmentation, and generation steps to ensure that every output is accurate, traceable, and aligned with organizational data and access controls.
Key technical capabilities powered by agentic RAG:
- Agentic retrieval orchestration:
Agentic RAG decomposes queries, rewrites them intelligently, performs multi-hop retrieval, selects optimal search pathways, and dynamically re-ranks results using domain rules, temporal relevance, role context, and user behavior.
- Agentic context augmentation:
Retrieved content is transformed by the agentic layer through summarization, deduplication, contradiction resolution, metadata alignment, and chunk optimization, ensuring the model receives structured, high-quality reasoning context.
- Grounded generation with agent oversight:
The generative model operates under agentic supervision, producing outputs strictly tied to validated evidence, with citations, metadata, and deep links that reflect the exact source of every piece of information.
- Enterprise data connectivity:
More than 100 connectors allow Agentic RAG to operate across CRMs, CMS platforms, cloud storage, productivity tools, and specialized systems, with RACL enforcement, field-level filtering, masking, authentication management, failover, and auto-sync.
- Advanced ingestion & processing pipeline:
Agentic RAG leverages a multi-stage pipeline capable of layout-aware extraction, OCR, HTML rendering, multimedia parsing, transcription, entity recognition, metadata enrichment, classification, and custom content analysis.
- High-quality embeddings & unified index:
Multi-vector embeddings, visual embeddings, domain-tuned models, hybrid lexical–vector indexing, and metadata-driven search create a robust index from which the agent can retrieve with high precision.
- Ontology + knowledge graph intelligence:
AI-driven ontology creation and automated knowledge graph construction give Agentic RAG a semantic understanding of enterprise concepts, relationships, and hierarchies, improving context-sensitive retrieval.
- Observability & governance:
All agentic reasoning steps, retrieval choices, chunk selection, augmentation actions, and generation decisions, are logged and measurable using LLM-based evaluation metrics, RAG recall/faithfulness scoring, audit trails, RBAC/ABAC, and compliance frameworks.
- Scalable hybrid deployment:
The Agentic RAG stack runs across SaaS, private cloud, on-prem, or hybrid deployments with distributed indexing, GPU-accelerated vector search, incremental updates, sharding, caching, and workload-aware scaling.
Learn more here - Enterprise Search Data
Conclusion
Agentic RAG represents a significant step forward in enterprise AI architecture because it combines structured retrieval, intelligent context augmentation, and agent-driven reasoning into a unified system. Instead of functioning as a static retrieve-and-generate pipeline, it operates as a continuous reasoning framework that interprets the task, acquires the required information, verifies its own outputs, and adapts its workflow based on real-time context.
This shift is important for modern enterprises that manage complex data ecosystems and require AI systems that can produce accurate, grounded, and operationally reliable outputs. Agentic RAG supports multi-step reasoning, deeper contextual alignment, and stronger precision in decision support, making it suitable for knowledge automation, customer assistance, research workflows, analytics, and other high-value use cases.
As organizations advance their AI strategies, architectures that incorporate agentic reasoning will become essential for building systems that are not only intelligent but also traceable, consistent, and aligned with real-world business logic. Agentic RAG delivers a practical and scalable path toward that future, enabling AI applications that perform with higher accuracy, better contextual awareness, and stronger enterprise readiness.






