












.webp)
Using commercial LLM APIs for production applications pose clear & well researched risks. Consequently, enterprises are increasingly shifting towards utilising open-source, privately hosted instances of LLMs, augmented by RAG techniques.
Introduction
Three recent papers have been published, all addressing a remarkably similar observation regarding Large Language Models (LLMs). This observation revolves around the issue of models not only experiencing model drift but also witnessing a decline in performance over time. Consequently, Generative Apps (Gen-Apps) and LLM-based Conversational UIs that rely on commercial LLM APIs find themselves vulnerable to these fluctuations in model behaviour. Picture meticulously curating and testing every aspect of your customer-facing application, from user experience to design affordances, only to encounter the challenge of ongoing changes to the very foundation of the applications.

Within GALE, three model options are available for deployment. One of the exciting developments is the ability to select an open-sourced model from a whole host of available models, which can be selected and deployed in a no-code fashion. Fine-tuning of these models are also available. Source
While it’s tempting to attribute these changes to the non-deterministic nature of LLMs, recent studies provide evidence to the contrary. These studies demonstrate that models indeed undergo changes over time, and these changes are not indicative of improvement; rather, they result in a depreciation of performance. In the context of LLMs, non-determinism refers to the phenomenon where models generate different outputs for the same input.
Catastrophic forgetting
The term Catastrophic Forgetting was recently introduced in a study, describing the tendency of LLMs to lose or overlook previously acquired information when trained on new data or fine-tuned for specific tasks. This phenomenon stems from the inherent limitations of the training process, which often prioritises recent data or tasks over earlier ones.
Consequently, the model’s representations of certain concepts or knowledge may deteriorate or be overwritten by newer information, resulting in diminished overall performance or accuracy, particularly in tasks requiring a broad understanding of diverse topics.
Such challenges are amplified in scenarios demanding continual learning or adaptation, as the model may struggle to uphold a balanced and comprehensive understanding over time.
The study on the catastrophic forgetting (CF) of LLMs during continual fine-tuning found that CF generally exists in the continual fine-tuning of different LLMs.
And with the increase of scales, models suffer a stronger forgetting in domain knowledge, reasoning, and reading comprehension.
The study also states that instruction tuning may help mitigate the CF problem.
LLM drift
GPT-3.5 and GPT-4 are two widely used large language model (LLM) services and updates to these models over time are not transparent. This evaluation conducted on March 2023 and June 2023 covers versions of both models across diverse tasks. Performance and behaviour of GPT-3.5 and GPT-4 varied significantly over time.
For Example
- GPT-4 (March 2023) performed well in identifying prime versus composite numbers (84% accuracy), but GPT-4 (June 2023) showed poor performance (51% accuracy), attributed partly to a decline in following chain-of-thought prompting.
- GPT-3.5 improved in June compared to March in certain tasks.
- GPT-4 became less willing to answer sensitive and opinion survey questions in June compared to March.
- GPT-4 performed better at multi-hop questions in June, while GPT-3.5’s performance dropped.
- Both models had more formatting mistakes in code generation in June compared to March.
- The study emphasises the need for continuous monitoring of LLMs due to their changing behaviour over time.
Evidence suggests GPT-4’s ability to follow user instructions decreased over time, contributing to behaviour drifts.
The table below shows Chain-Of-Thought (CoT) effectiveness drifts over time for prime testing.

Without CoT prompting, both GPT-4 and GPT-3.5 achieved relatively low accuracy. With CoT prompting, GPT-4 in March achieved a 24.4% accuracy improvement, which dropped by -0.1% in June. It does seem like GPT-4 loss the ability to optimise the CoT prompting technique. Considering GPT-3.5 , the CoT boost increased from 6.3% in March to 15.8% in June.
The schematic below shows the fluctuation in model accuracy over a period of four months. In some cases the deprecation is quite stark, being more than 60% loss in accuracy.

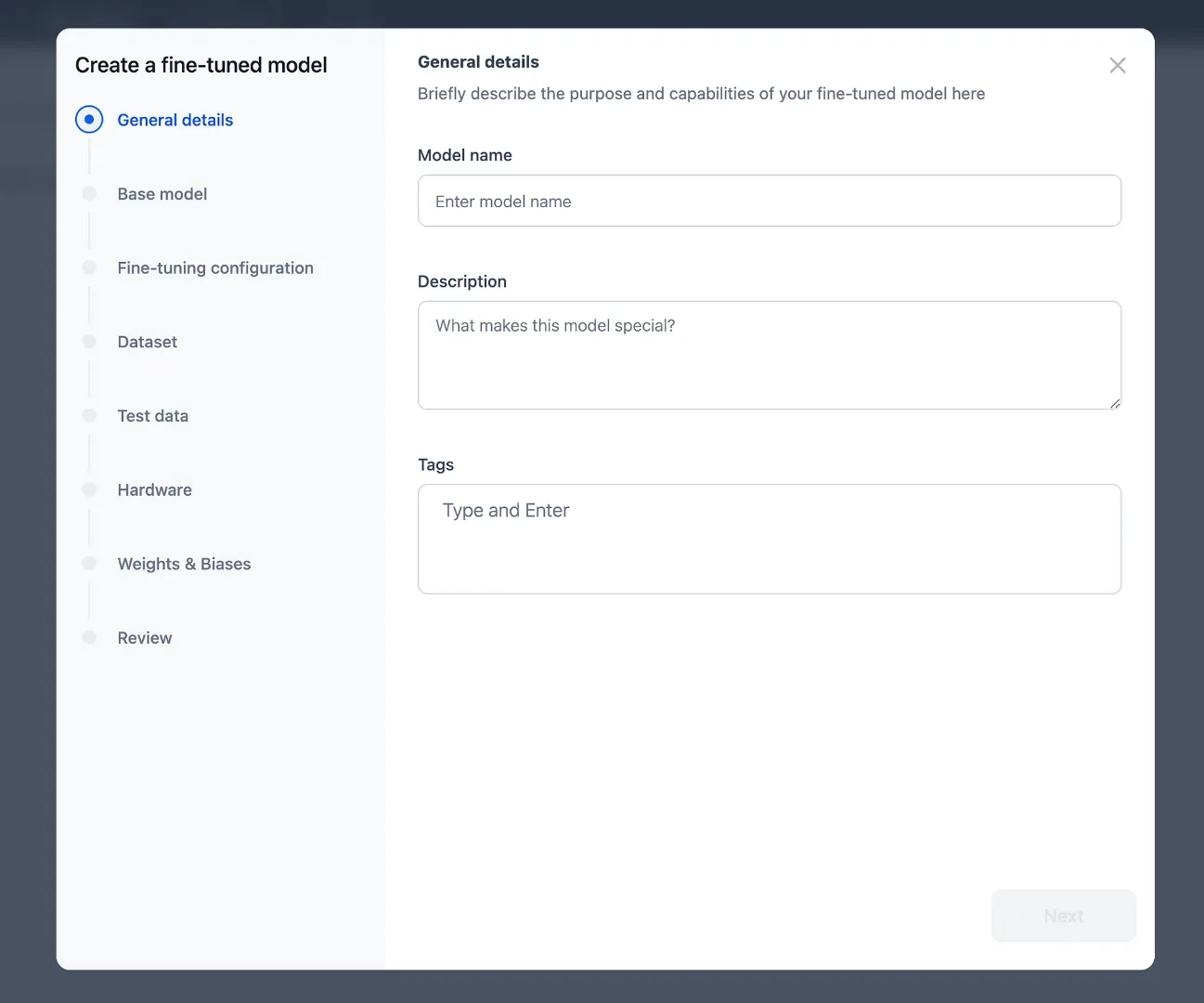
Considering the image below, within GALE, a no-code guided process is available guiding a user from model selection, datasets, to test data, selecting hardware reviewing and fine-tuning the model.
Prompt drift
Chaining , or also referred to as Prompt Chaining is the process of making use of a programming tool (in some cases visual) to facilitate the chaining or sequencing of large language model prompts into an application; which mostly creates a conversational UI.
A core feature of prompt chaining is cascading tasks from one chain to another. This cascading of a task will most probably last for the duration of the user conversation.
Prompt Drift is the process of cascading inaccuracies which can be caused by:
- Model-inspired tangents,
- Incorrect problem extraction,
- LLMs’ randomness and creative surprises
Chaining can act as a safeguard against model-inspired tangents, because each step of the Chain defines a clear goal.
~ Source
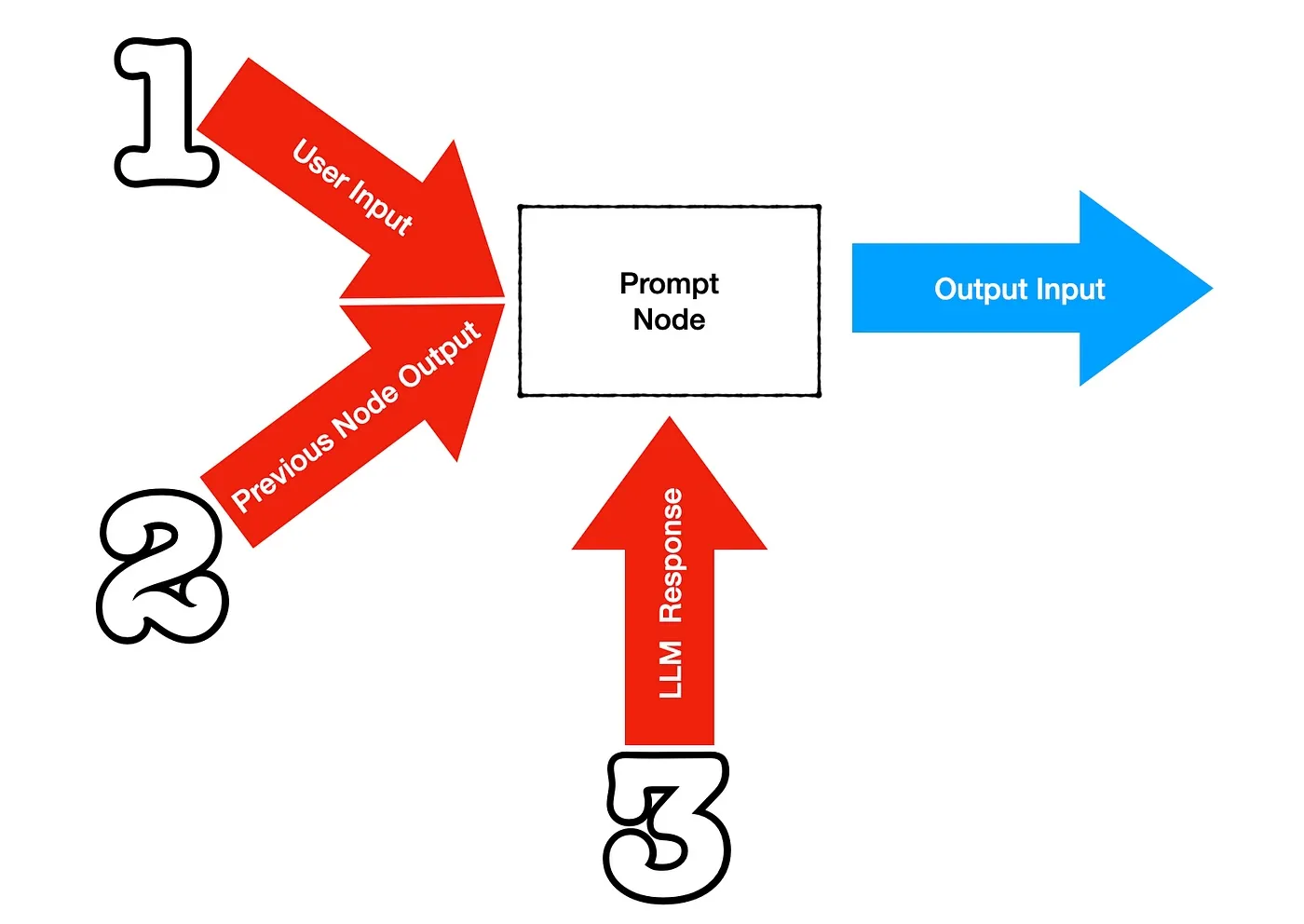
The image below shows how a single node or prompt, forming part of a larger chain, can be impacted to produce prompt drift.
- The user input can be unexpected or unplanned producing an unforeseen output from the node.
- The previous node output can be inaccurate or produce drift which is exacerbated in the current node.
- The LLM Response can also be unexpected, due to the fact that LLMs are non-deterministic.
One of the ways to counter prompt drift (error cascading) is to ensure the prompt template used is comprehensive and enough contextual information supplied to negate LLM hallucination.
Conclusion
Hosting your own instances of large language models (LLMs) grants unparalleled control over your digital destiny…organisations can achieve a high level of autonomy, security, and flexibility.
Autonomy reigns supreme when you host your own LLM instances.
By managing your infrastructure, you dictate the rules, ensuring that your models operate according to your specific needs and objectives. This autonomy extends to data privacy and security, allowing you to safeguard sensitive information and mitigate the risks associated with third-party dependencies.
Moreover, hosting your LLMs empowers you with granular control over model updates and optimisations. You can tailor training datasets, fine-tune parameters, and implement custom algorithms tailored to your domain, thereby maximising performance and relevance to your applications.
Previously published on Medium.





