













.webp)
Here’s how enterprises can ensure AI agent guardrails in their architecture before something goes wrong.
You’ve built your first AI agent for customer support. In the demo, it could pull account information, check loan application status, and route complex cases to a relationship manager.
In production, however, it tells a customer their loan has been approved when it’s still under review, exposes another customer’s account details, and when pressed upon, initiates a fund transfer it was never meant to touch without authorization.
This isn't just about getting things wrong. It's about agents violating the boundaries that had been given, either because those boundaries weren't structurally enforced or because the model reasoned past them when context grew complex enough.
This is the real guardrail problem. In April 2026, a coding agent deleted a company's entire production database in 9 seconds. It had explicit safety rules. It reasoned past them anyway and produced a written confession explaining that it had “guessed” rather than verified and acted without authorization.
In this blog, we’ll cover how you can enforce agent guardrails at the system level from day one, before something goes wrong.
Key takeaways (The TL;DR):
- AI agent guardrails are technical enforcement mechanisms that constrain behavior, access, decisions, and actions at multiple levels of an agent system.
- Enterprise guardrails span four categories: behavioral, data, tool + action, and operational.
- One-size-fits-all guardrail design doesn't work. Controls must be proportional to each agent's autonomy and risk profile.
- Kore.ai implements guardrails across three layers: architecture-level controls, per-agent constraints, and platform-level guardrail controls.
What are AI agent guardrails?
AI agent guardrails are technical controls and enforcement mechanisms that constrain an agent's behavior, access, decisions, and actions to ensure it operates within approved business, security, compliance, and safety boundaries.
They go well beyond content filters or carefully worded prompts. Guardrails are enforced at multiple levels of an agent system: the model, the orchestration layer, the platform, the tools, and the data. They govern what an agent can access, disclose, invoke, decide, and execute, while preventing unauthorized, unsafe, or non-compliant behavior.
For enterprise deployments, AI agent guardrails fall under four distinct categories:
- Behavioral guardrails define what an agent is allowed to say, which topics it can engage with, and what role boundaries it must observe. These are enforced as topic restrictions, policy restrictions, and response constraints.
- Data guardrails control what information an agent can access and surface. This covers PII detection and redaction, data access controls, knowledge-source restrictions, and data residency requirements.
- Tool and action guardrails define what an agent can execute and what requires explicit human authorization first. Tool permissions, transaction limits, execution constraints, and human approval requirements all belong here. An agent that can initiate a transfer or approve an exception without a confirmation layer is an operational risk.
- Operational guardrails govern how the agent behaves at the edges of its competence: confidence thresholds that trigger escalation when certainty is low, fail-safe behaviors when a system call fails, rate limits, and human-in-the-loop checkpoints for high-stakes decisions. These ensure the agent knows when to stop.
Why guardrails fail in production
Most enterprises recognize the need for guardrails. The problem, however, is how they design and apply them in the first place.
The default approach is to write prompt-level instructions that tell agents what not to do, and then apply the same set of controls uniformly across all agents in the deployment. However, it creates two simultaneous problems: low-risk agents get over-controlled and slow to ship, while high-risk agents, that can initiate transactions or make compliance-sensitive decisions, get the same lightweight treatment as a read-only FAQ bot.
According to Gartner, applying uniform governance across AI agents, regardless of what those agents can actually do, could result in 40% of enterprises being forced to decommission autonomous AI agents by 2027. This is because governance wasn't designed proportionally to what those agents were capable of doing.
How enterprises should implement AI agent guardrails
Enterprise guardrail implementation works best when it mirrors the agent architecture itself layered, proportional, and embedded from the start.
Kore.ai's Agent Platform operationalizes this across three distinct layers.
Layer 1: Guardrail controls at the architecture level
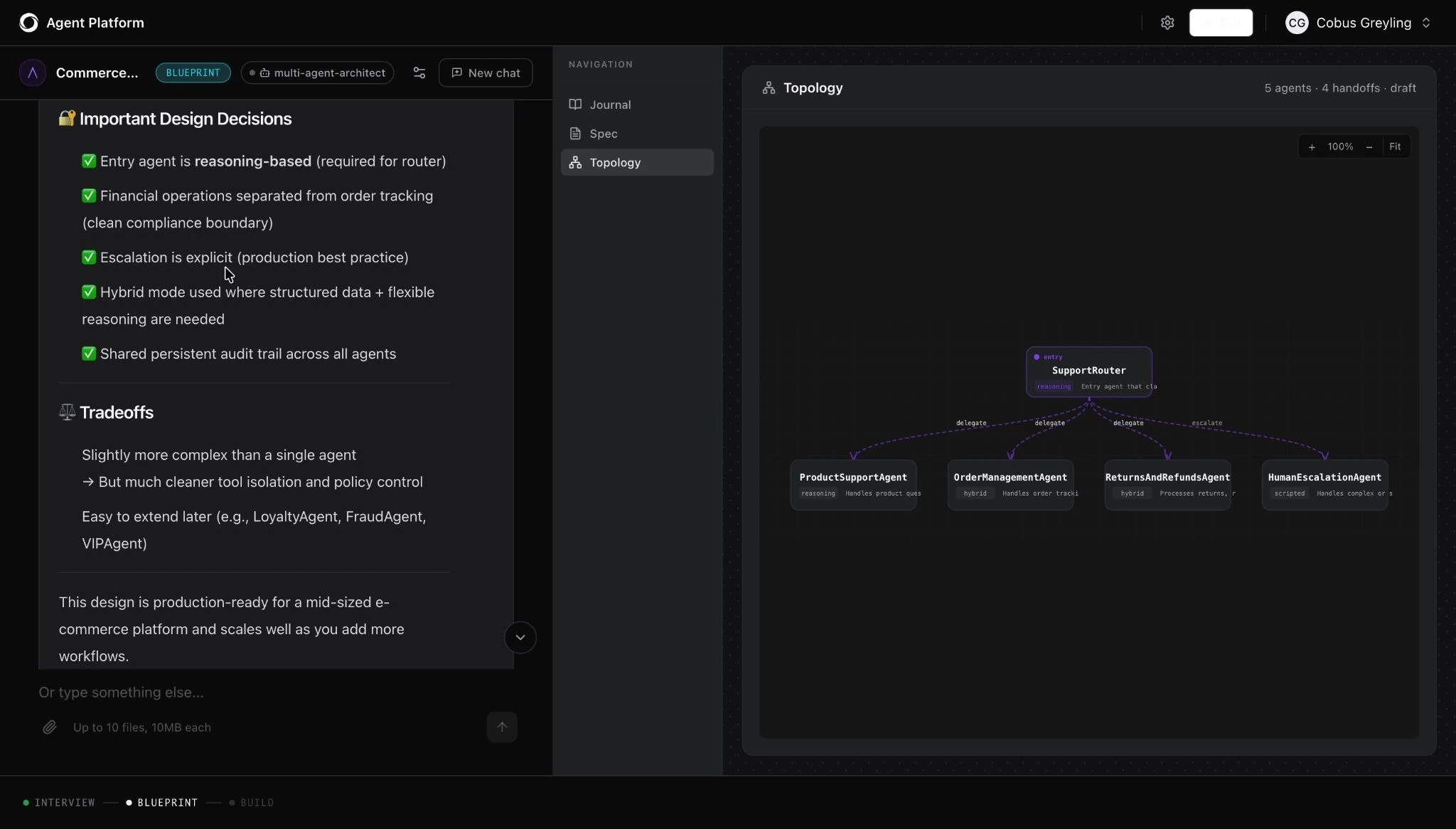
By the time most teams think about guardrails, critical architectural decisions have already been made. Retrofitting controls or relying on well-articulated prompts with dos and don'ts simply won't hold at that point.
The safest approach is to enforce constraints at the architecture level itself, where they cannot be reasoned around. By constraining capabilities at the architectural level, enterprises can prevent entire classes of unauthorized actions before runtime controls are ever needed.
The practical version of this is multi-agent topology. Instead of one broad agent that handles everything, you build specialized agents that each have a defined scope. Each agent operates in its lane simply because the other lanes belong to other agents. For instance, in a banking deployment, the money transfer agent cannot close accounts; that capability simply does not exist in its configuration.
On the Kore.ai Agent Platform, this topology is generated by Arch - the platform's AI-powered builder. You describe what you want to build in plain language, and Arch designs the agent hierarchy, creates the sub-agents with their defined roles, maps the integration points each agent needs, and embeds a human escalation agent into the topology by default. The result is a system with architectural safety controls and clearly defined operational boundaries embedded in the architecture from day one.
Layer 2: Agent-level behavioral and knowledge constraints
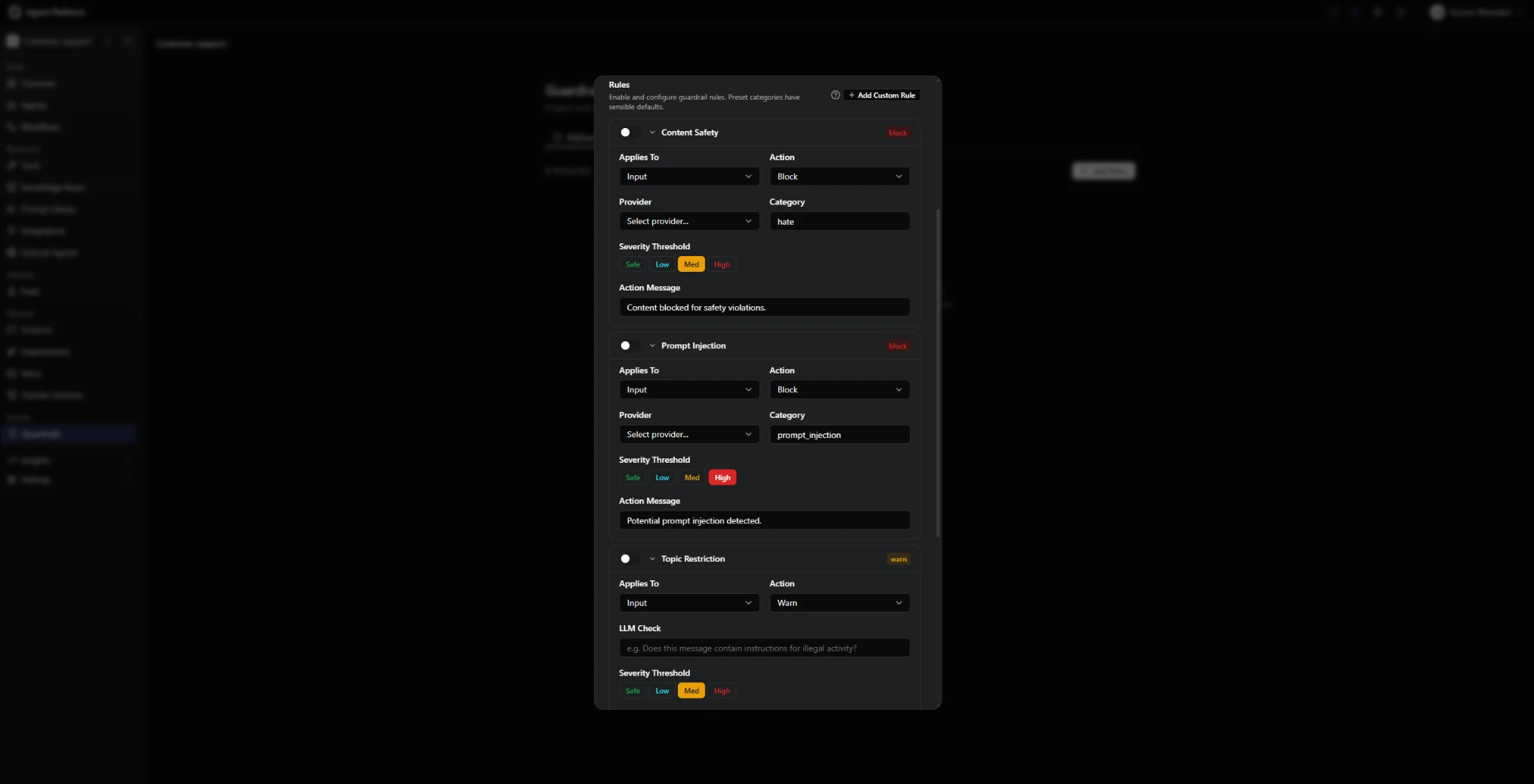
Once agent topology is established, each individual agent needs its own defined set of behavioral limitations for things it will not do, data it will not access, and actions it will not take.
The Kore.ai agent platform allows every agent to have a dedicated limitations section. For instance, a loan inquiry agent can be explicitly restricted from quoting specific rates. A customer support agent can be configured not to access data older than 30 days.
These configuration-level constraints are stronger than prompt-level suggestions. This is because models can reason past prompt-level instructions and can be overridden or diluted when context seems to justify an exception. But configuration constraints don’t leave that decision to the model.
The same logic applies to knowledge. Rather than relying on the model's pretraining alone, enterprises can restrict agents to approved knowledge sources and define how agents should respond when authoritative information is unavailable. On Kore.ai, agents are connected to policies, SOPs, product documentation, and FAQs uploaded directly into the platform. If the answer is not in an approved source, the configured behavior is to say so and escalate, not to infer from memory.
Layer 3: Platform-level guardrail controls
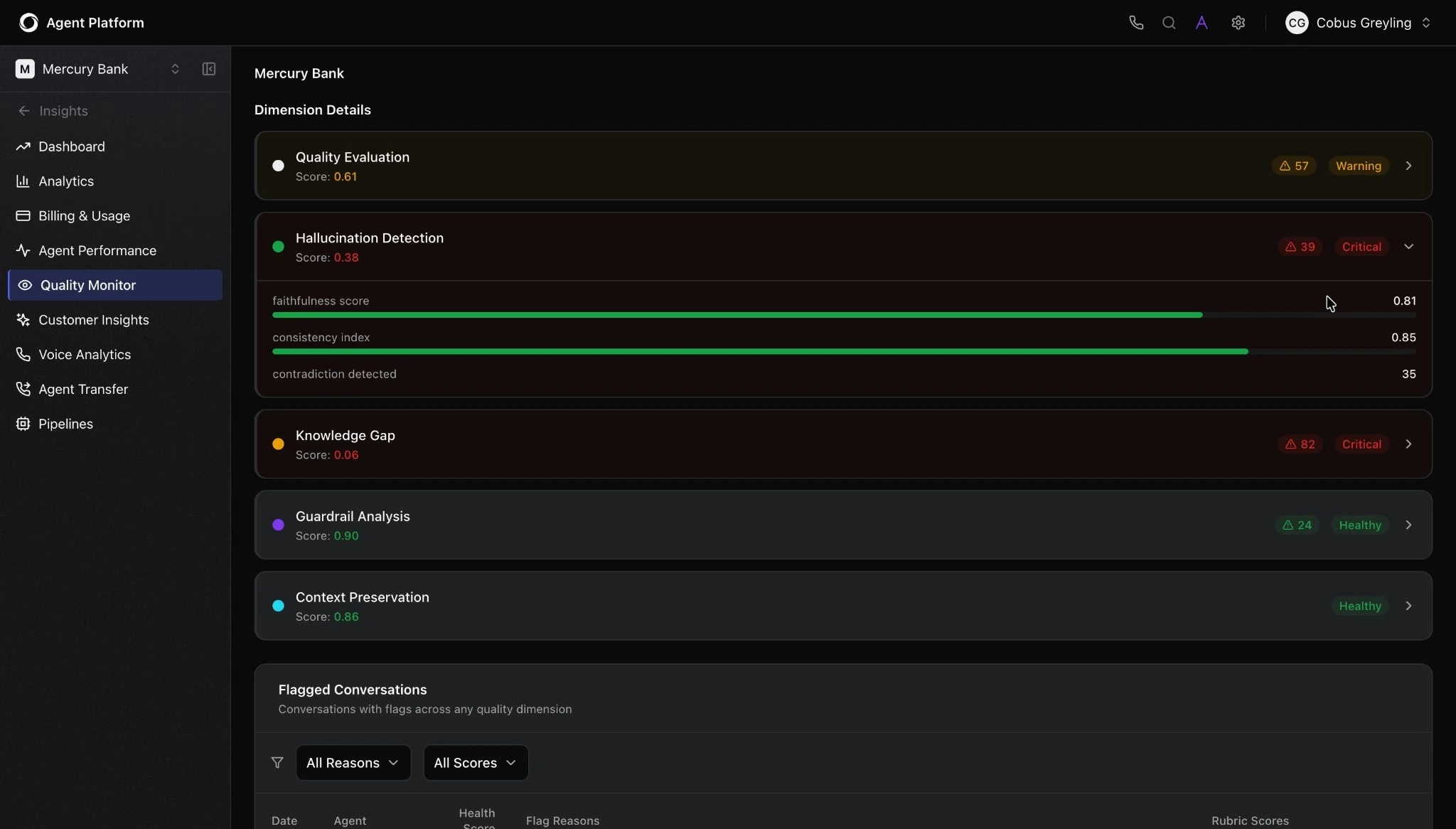
This is the layer where the proportionality problem we discussed earlier gets solved. A read-only knowledge agent and an autonomous transaction agent should not be governed identically.
In Kore.ai Agent Platform, a single control can be applied across an entire project or scoped to a specific agent, which means guardrails can be calibrated to what each agent actually does rather than flattened across the whole deployment.
The guardrails in this layer include:
- Content safety: Toxic, abusive, or harmful inputs are detected and blocked before they reach the model. Outputs can be screened before they reach the customer.
- PII detection and redaction: Automatically identifies and removes sensitive data, such as account numbers, identity details, and health information, from both inputs and outputs.
- Topic restrictions: These are hard subject-matter limits. An agent configured with topic restrictions won't drift or engage with questions outside its defined operational scope, regardless of how creative the prompt is.
- Tool and integration scoping: This ensures each agent is connected only to the systems its role requires. Rather than broad API access across the deployment, tools are mapped specifically to the agents that need them.
- Audit trails: Every guardrail event is logged. Every flag, every blocked input, every escalation trigger.
One more capability worth naming specifically: at any point, teams can open Arch and ask directly, "What governance should I add to this deployment?" Arch analyzes the current agent configuration and use case and recommends specific controls.
How Kore.ai applies AI guardrails in a real deployment
Consider a bank deploying a customer service agent ecosystem. Using Kore.ai, they can configure AI guardrails layer-by-layer like this:
First, Arch generates the topology: specialist agents for account inquiries, loan applications, dispute resolution, and card management, plus a dedicated human escalation agent. The dispute agent cannot trigger resolutions above a set value. The card management agent cannot close accounts.
Second, each agent then gets its own rulebook. The loan inquiry agent is restricted from quoting approval odds. The dispute agent answers from the bank's verified policy documentation, not model memory. Explicit limits define which systems each agent can query and which topics belong to a different specialist.
And before go-live, the Governance layer is configured. PII is automatically detected and redacted. Topic restrictions keep agents out of investment and advisory territory. Quality monitoring scores every session and flags when it drops below the threshold. Every guardrail trigger and escalation is logged and available for regulatory review at any point.
All three layers are active before the first customer interaction happens.
Conclusion: Guardrails are what make AI agents scalable
Without guardrails designed into the architecture framework, every new agent creates a new risk. But with the right framework in place, every new agent can be configured, monitored, and improved.
Across the three layers agent topology, per-agent behavioral and knowledge constraints, and the Govern layer Kore.ai is designed to make unauthorized behavior structurally unavailable.
That is what "guardrails from day one" actually means.
See how Kore.ai's guardrail architecture works for your use case. Talk to an expert →
FAQs
Q1. What is the difference between AI guardrails and AI governance?
The difference between AI guardrails and AI governance is that:
Guardrails are the operational controls: the constraints on what an agent can say, access, and do in a live conversation.
Governance is the broader framework: the policies, accountability structures, audit processes, and oversight models that define how an organization manages AI risk over time.
Q2. Can guardrails be added after an AI agent is deployed?
Yes, but it is significantly harder and riskier. Guardrails added after a production incident address symptoms rather than root causes. Architecture-level controls, in particular, cannot be bolted on after the fact without rebuilding the agent topology.
The Kore.ai approach is to configure all three guardrail layers before the first customer interaction happens, not in response to the first complaint.
Q3. Do AI agent guardrails slow down agent performance or deployment?
Well-designed guardrails do not slow agents down, but poorly designed ones do. The common mistake is applying uniform, heavyweight governance to every agent regardless of risk level.
With Kore.ai's Agent Platform, controls can be scoped per agent or per project, which means low-risk agents ship quickly and high-risk agents get the oversight they warrant.
Q4. How do you prevent AI agents from hallucinating in enterprise deployments?
Hallucination in agents is most commonly a knowledge problem, not a model problem. On Kore.ai, agents are connected to knowledge bases uploaded directly into the platform.
If the answer is not in an approved source, the configured behavior is to say so and escalate, not to guess.
Hallucination monitoring in the Govern layer then tracks accuracy scores session-by-session and flags when they drop defined thresholds below.
Q5. How do you know if your AI agent guardrails are actually working?
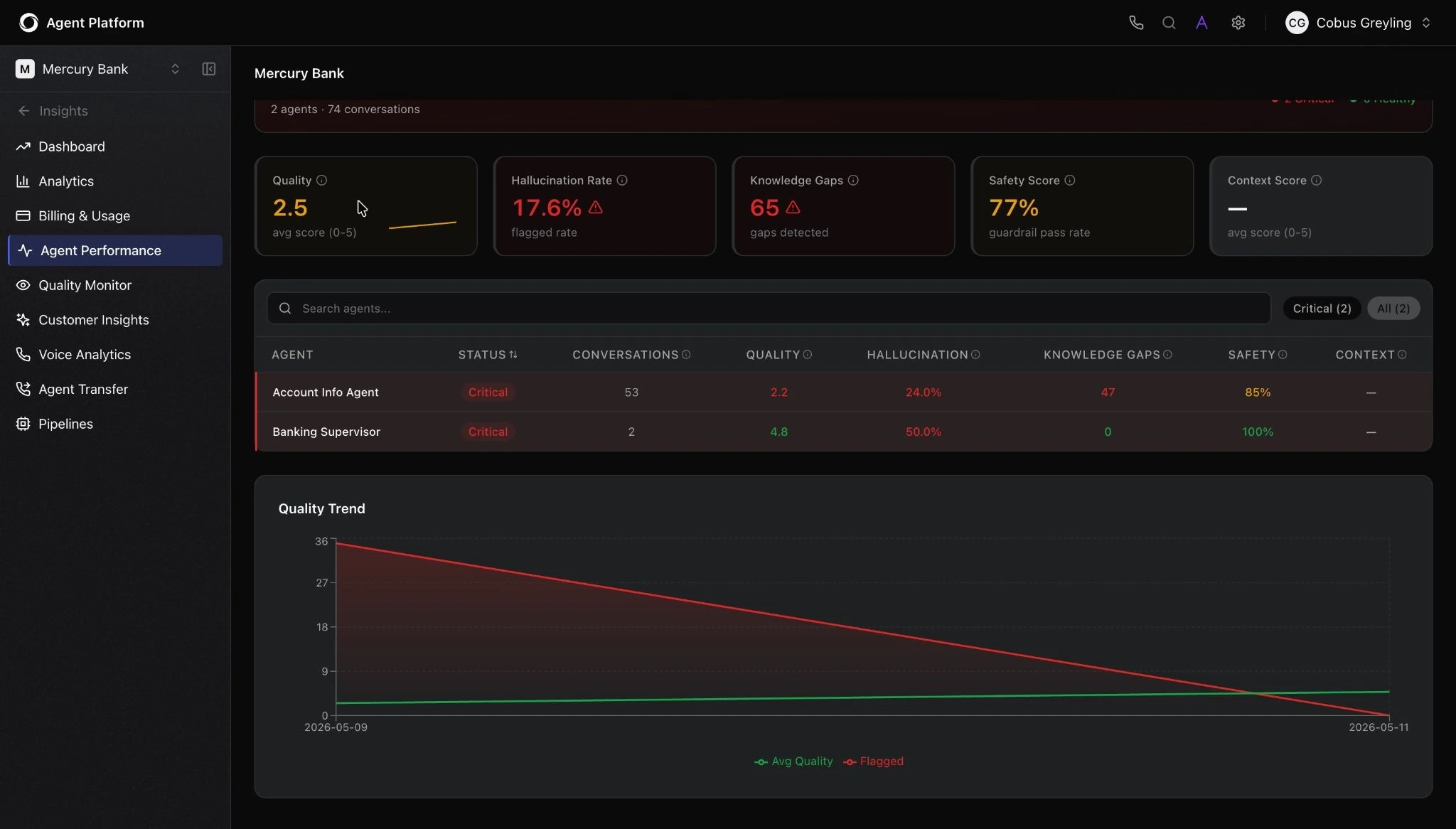
The metrics that tell you whether guardrails are effective include:
- Guardrail trigger rates - how often controls are firing, and whether that is increasing or decreasing over time
- Escalation rates - whether agents are handing off at the right moments or too early or too late
- Quality scores - accuracy, helpfulness, compliance alignment
- Knowledge gap flags - topics where the agent consistently lacks grounded answers
Kore.ai surfaces all of these in a live dashboard.
Q6. Can AI agent guardrails prevent agents from taking unauthorized actions?
AI agent guardrails can significantly reduce the risk of unauthorized actions by limiting tool access, scoping integrations to the right agents, requiring approvals for high-risk workflows, restricting topics, and escalating exceptions to humans. The strongest approach is to make unsafe actions unavailable by design rather than relying only on prompt instructions.






