












.webp)
A number of advancements have been made in the area of prompting techniques, enabling LLMs to significantly improved performance on a variety of domains.
Overview
Lately there has been much focus on methods to optimise LLMs using a gradient-free (not using fine-tuning) approach. An astute approach to LLM implementation would be to use both gradient-free and gradient in concert while orchestrating multiple LLMs.
This study clearly state that the purpose of this research is not to replace gradient approaches, but rather explore to what extent prompt engineering can be leveraged to improve LLM performance. OPRO is not intended to outperform gradient-based optimisation.
This study also highlights the fact that LLMs are sensitive to different prompt formats, and that optimal prompt formats are model and task specific.
Another area of focus was stability, or which can also be thought of as reliability. To improve stability, OPRO follows a method where the LLM is used to generate multiple solutions at each inference (optimisation step), allowing the LLM to simultaneously explore multiple possibilities and quickly discover promising directions to move forward.
This creates a process of convergence to an optimal solution; So OPRO can be thought of as a prompt based optimisation trajectory.
Initial considerations
This study again shows the flexibility and utility of LLMs, and to what extent Prompt Engineering can be leveraged to achieve tasks not envisioned previously.
One of the challenges with LLMs in production is inference-time latency; and this iterative process seems to be an excellent idea for prompt engineering optimisation, crafting prompts which outperform human-designed prompts. Including prompts which are task and model specific.
At this stage I cannot see this being used at run-time in a production environment; OPRO can work well at design-time.
I get the impression as prompt engineering techniques develop, especially considering the newly released studies, that a more iterative approach is being followed which has cost, latency and complexity considerations.
It would be convenient if a UI existed which sits between a playground and autonomous agents; where these prompt engineering techniques can be experimented with. I envisage this as a more configurable playground where routines can be defined and a process or number of iterative loops are possible.
Prompts optimised by OPRO outperform human-designed prompts by 8% to 50% at certain tasks.
— Source
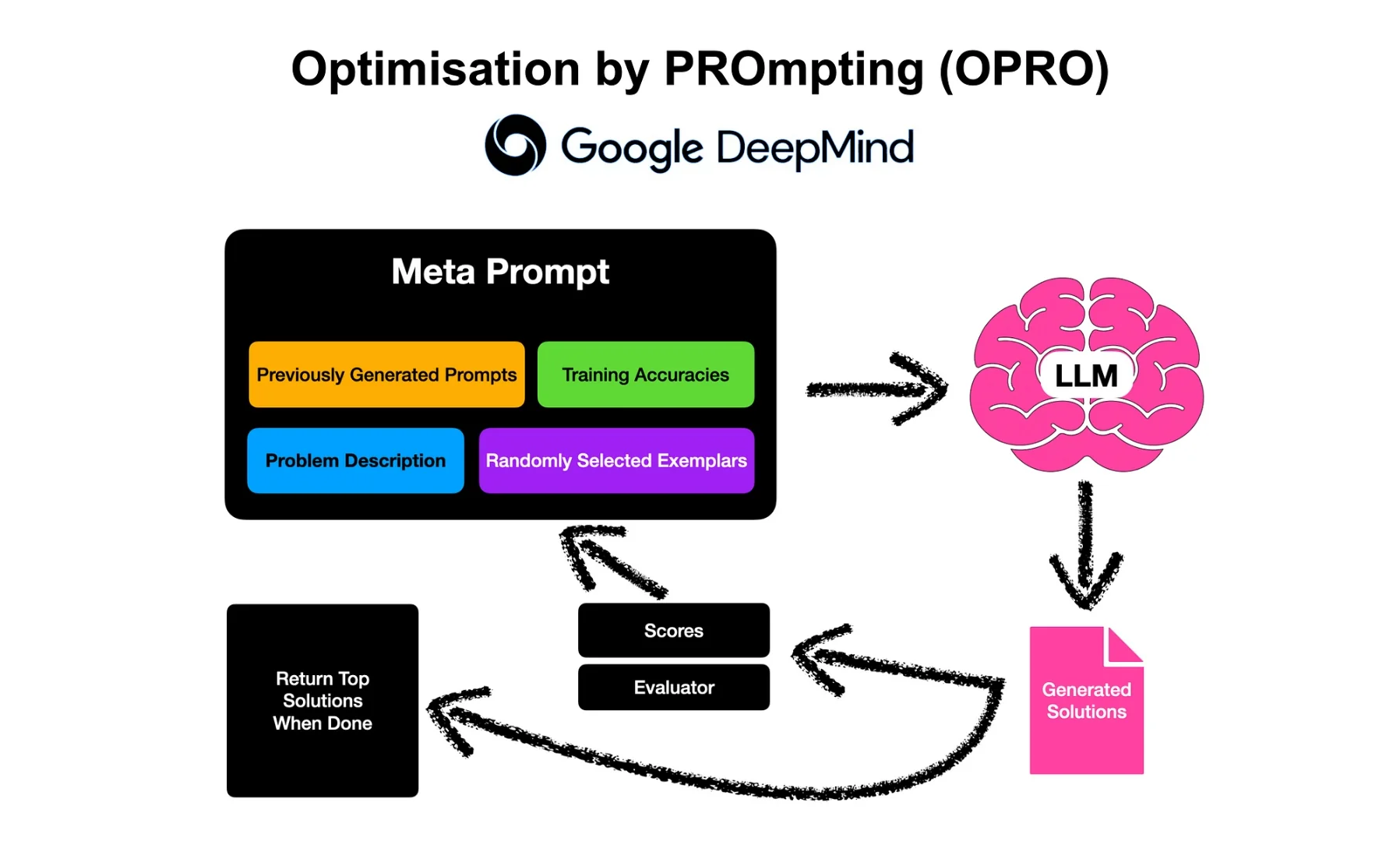
The study states that OPRP follows an optimisation process with the LLM, which starts from 5 conMeta Prompt Example
The meta-prompt OPRO makes use of, has a four components, with the configuration shown below…
Meta-prompt = meta-instructions + solution-score pairs + meta-instructions + optimisation task & output format + meta-instructions
Meta-Instructions
This part sets the context for the LLM. It defines what the optimization task is and how the LLM should go about generating a new solution.
Objective: Defines the optimization goal (e.g., "generate a new instruction that achieves a higher accuracy").
Constraints/Guidance: Includes general guidance or desired properties for the new solution (e.g., "the instruction should be concise," or providing examples of how the new instruction will be applied).
Solution-score pairs
This is the in-context data that the LLM uses to learn the optimization landscape.
Content: A list of previously generated solutions (e.g., prior prompts or instructions) paired with their corresponding performance scores (e.g., task accuracy).
Function: This trajectory is typically sorted by score (often in ascending order, from worst to best). This allows the LLM to identify patterns in high-scoring solutions and build upon them, enabling it to exploit the search space effectively.
Meta-Instructions
The meta-prompt often includes a final set of instructions to ensure the LLM's output is correctly formatted and ready for the next step of the optimization loop.
Purpose: Clearly specifies the required output structure (e.g., "Only output the new instruction/solution without any other commentary or text"). This ensures the output can be easily extracted and evaluated.
Optimisation task & output format
This is the final, specific call to action that triggers the LLM to perform the next optimization step. While sometimes merged with the initial meta-instructions, it essentially prompts the model to generate the new solution.
Action: Directs the LLM to apply the provided instructions and trajectory to generate a novel solution (e.g., "Now, generate the next new instruction").
Meta-Instructions
Write your new text that is different from the old ones and has a score as high as possible. Write the text in square brackets.
The complete prompt concatenated:
It is the entire input fed to the Large Language Model, consisting of the problem definition, the historical trajectory of scored solutions, and explicit instructions for generating and formatting the next, optimized solution. It is the full operational instruction set enabling the LLM to perform in-context optimization. "The meta-prompt contains two core pieces of information:
- The previously generated prompts with their corresponding training accuracies.
- The optimisation problem description, which includes several exemplars randomly selected from the training set to exemplify the task of interest.
OPRO methodology
OPRO follows a process of leverages a LLM to gradually generate new prompts via an iterative optimisation process.
Recent work considered the discipline of LLMs generating and improving on human-level prompt engineering. What makes OPRO different is that it is an iterative process, each optimisation step generates new prompts that aim to increase the test accuracy based on a trajectory of previously generated prompts.
OPRO follows a full optimisation trajectory, OPRO enables the LLM to gradually generate new prompts that improve the task accuracy throughout the optimisation process, where the initial prompts have low task accuracies.
The optimal prompt formats can be model-specific and task-specific.
— Source
With a variety of LLMs, the study demonstrates that the best prompts optimised by OPRO outperform human-designed prompts by up to 8% on GSM8K, and by up to 50% on Big-Bench Hard tasks.
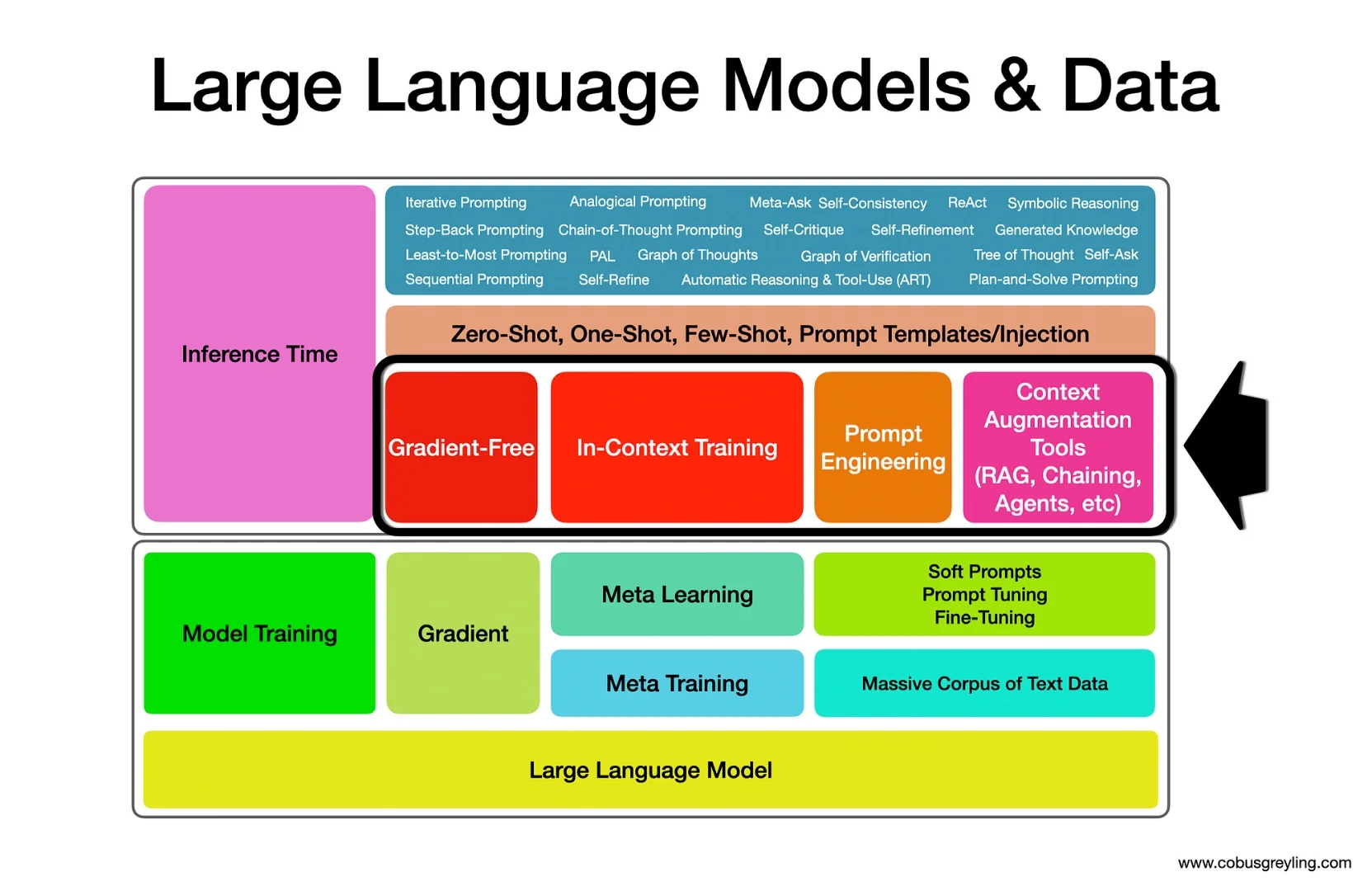
The image below show where OPRO fits into the data delivery process of Large Language Models, in the gradient-free, in-context sphere.
Find the study here.





