












.webp)
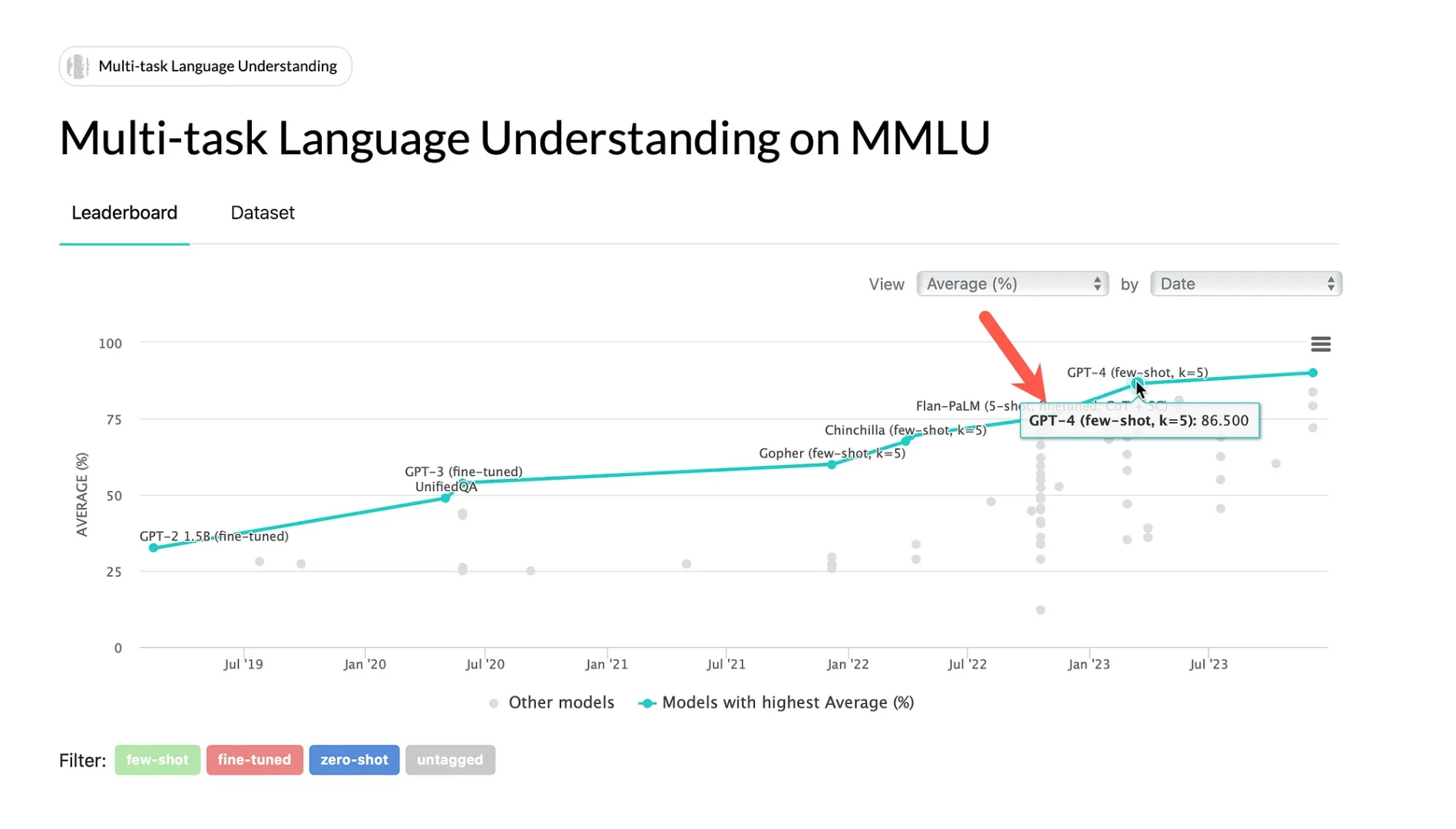
With one of the Google LLM launches, Gemini Ultra was shown as having exceeded human expert level using the MMLU measurement.
Introduction
Considering the image below, I can remember in 2017 when it was illustrated how the word accuracy rate of Google ML Voice Recognition exceeded that of human level. With the human accuracy threshold being at 95%, and Google ASR reaching 95%+
Fast forward six years, and Large Language Models (LLMs) are reaching human expert levels according to the MMLU measurement.
But not only that, LLMs incorporate reasoning, in-context learning, are general knowledge intensive NLP systems, which can also be trained on specific knowledge, with natural language generation (NLG) capabilities.

Back to MMLU
MMLU is underpinned by a massive multitask test-set consisting of multiple-choice questions from various branches of knowledge.
The test spans the humanities, social sciences, hard sciences, and other important areas; totalling 57 tasks.
The 57 tasks are spread over 15,908 questions in total, which are split into a few-shot development set, a validation set, and a test set.
- The few-shot development set has 5 questions per subject.
- The validation set may be used for selecting hyper-parameters and consists of 1540 questions.
- The test set has 14079 questions.
- Each subject contains 100 test examples at the minimum, which is longer than most exams designed to assess people.

Findings from Jan 2021
- Most recent models have near random-chance accuracy.
- GPT-3 models improve over random chance by almost 20% on average.
- For all 57 tasks, the best models still need substantial improvements before they can reach expert-level accuracy.
- Models frequently do not know when they are wrong.
- Models have near-random accuracy on some socially important subjects such as morality and law.
- State-of-the-art models still struggle at learning and applying knowledge from pre-training.
- Future models need to improve their understanding on what is legal and what is ethical.
- Worryingly, we also find that GPT-3 does not have an accurate sense of what it does or does not know since its average confidence can be up to 24% off from its actual accuracy.
Model Confidence
Considering the image below, the study found that GPT-3s confidence is a poor estimator of accuracy and the model can be off by up to 24%.

The study found that GPT-3 is aware of certain facts; hence being trained on those facts, but GPT-3 does not apply the facts in reasoning. These findings are such a good explanation why In-Context Learning (ICL) can so effectively be applied via a chain-of-thought process.
Multimodal understanding
The study’s comments on multi-modal models are also interesting…
While text can effectively convey a vast array of ideas about the world, numerous crucial concepts rely heavily on alternative modalities like images, audio, and physical interaction.
With the advancement of models in processing multimodal inputs, benchmarks need to adapt to this evolution.
A potential benchmark for this purpose is a “Turk Test,” comprising of Amazon Mechanical Turk Human Intelligence Tasks. These tasks are well-defined and demand models to engage with flexible formats, showcasing their understanding of multimodal inputs.
Model limitations
Here is a summary of model limitations found by the study…
- LLMs are poor at modelling human disapproval, as evident by the low performance on the Professional Law and Moral Scenarios tasks.
- Models also have difficulty performing calculations.
- It is unclear whether simply scaling up existing language models will solve the test.
- Training data may also become a bottleneck, as there is far less written about esoteric branches of knowledge than about everyday situations.





