












.webp)
Memory drift is one of the main reasons your AI agents underdeliver in production and the fix has nothing to do with the model you're running.
If you've spent any real time working with AI, you've probably run into this problem at some point. Say, you're in the middle of writing something, and you’ve asked the AI to stick to a particular tone.
At first, it works exactly as expected. But a few steps later, the tone slips. The instruction you gave earlier seems to fade, and the AI starts doing its own thing.
Your first instinct is to blame the model. Maybe it’s not smart enough. So you repeat the instruction. And again, it works…for a bit. Then it drifts again.
Here’s what’s actually happening. Your agent's working memory has a fixed capacity. As the session grows and more context gets added, the agent needs to make room for what’s new. So it compresses. It lets older things blur to make space for newer details. Your instruction from ten exchanges is still there, but it’s no longer strong enough to consistently guide the output.
This is memory drift. It happens when AI agents lose reliable access to earlier instructions, either because the agent summarizes older history to stay within token limits or because it gives less attention weight to older information as context grows. In both cases, the agent keeps working from an increasingly blurred version of what it was originally told, with no way to know how much fidelity has been lost.
In an enterprise, memory drift is one of the biggest reasons AI agents work in a demo but struggle to hold up in production.
What’s actually happening inside an agent
Now move that same behaviour from your ChatGPT window into an enterprise environment, where AI agents process thousands of decisions a day.
At the start, the agent has a clear operating context. It knows the policies, rules, approval thresholds, and regulatory requirements that should guide its decisions. Early on, that context is sharp, and the outputs reflect it.
But enterprise workflows are long. Agents burn thousands of tokens across extended sessions. As context fills up, the agent starts compressing. It blends older facts with newer ones, and at no point can the agent go back and check what's been left behind.
That is the key issue. The agent does not know its memory has become less precise. It continues operating confidently, optimizing for what feels locally correct in the moment rather than what was globally specified at the start.
Prasanna Arikala, Kore.ai's CTO, precisely describes the drift in agents:
“As tasks grow longer, earlier decisions blur into compressed memories, and the agent starts optimizing for local completion rather than system-level correctness. That is exactly where drift begins.”
What you end up with is an agent that is simultaneously too confident and too imprecise. Too confident because it gets no signal that its memory has degraded. Too imprecise because the rules it's working from are no longer quite the ones you gave it.
No source of truth = Unreliable decisions
Memory drift is not hallucination. The agent isn't fabricating policies or applying rules that never existed. Memory drift is precision loss, not fabrication.
Let’s understand this with a simple example. Consider a bank that deploys an AI agent to process loan applications. At deployment, the agent is given a clear instruction: applicants with a credit score above 740 qualify for the prime lending rate. For the first several months, it applies this precisely.
Then the festive season arrives. The bank runs a six-week promotional scheme, temporarily lowering the threshold to 720. The agent fetches the new policy and applies the new threshold correctly across thousands of applications during the festive season.
The scheme closes in January. The threshold goes back to 740. Now here is where drift enters.
The limited 720 threshold from the festive season doesn't disappear from its memory. It fades into the background of the agent's working memory, still present, still shaping how it interprets applications in that range.
In February, an applicant with a score of 725 comes in. Under current policy, they don't qualify. But the agent is working from a compressed blend where 720 was the threshold for a significant period. The line between two thresholds, in the agent's memory, is no longer clean, and therefore, it approves the application.
The failure here is that the agent had nowhere to go to check. No persistent, external source of truth it could consult mid-task to confirm which rule was currently in force. No reference point outside its own compressed memory. It could only work from what was inside its own context window, and that, by this point, was no longer precise enough to be trusted.
This isn’t theoretical. In fact, in February 2026, Summer Yue of Meta's Superintelligence Labs connected an AI agent to her primary inbox with a clear instruction: “suggest what to archive or delete, and wait for approval before acting”. On the larger inbox, the agent compacted older context, lost that safety instruction, and started deleting emails anyway. The rule was not wrong; it just stopped surviving inside the agent's working memory.
Memory drift doesn’t happen in just one way
Memory drift doesn’t show up as one neat failure mode. In enterprise AI deployments, it tends to appear in a few different forms, each of which has a different cause and produces a different category of problem.
Temporal drift is the blurring of ‘when.’ This is when the agent keeps working from rules that were once valid but are no longer current. A temporary lending threshold, a festive exception, or a transitional compliance provision remains present in memory long after it should have stopped governing decisions.
That creates a regulatory traceability problem. In banks, for instance, the lending criteria applied to a loan application must be traceable to the policy that was actually in force at the time. When an agent applies an expired rule, the audit trail becomes hard to defend.
Semantic drift is the blurring of ‘meaning.’ Here, the issue is not that the agent remembers the wrong rule, but that the meaning of the rule softens as memory compresses. For instance, a precise instruction like “self-employed applicants below this threshold require manual review” gradually becomes something looser in memory, more like “self-employed applicants are higher risk.” The output can still sound perfectly coherent, but the agent is no longer applying the rule with the same precision it started with.
That creates a consistency problem. A loan application assessed six months apart can receive different outcomes because the agent's interpretation of the policy has changed. Semantic drift is slower and nearly impossible to detect without deliberately comparing current decisions against the original policy definition.
Behavioural drift is the blurring of ‘pattern.’ This shows up when the agent has already processed thousands of applications and has now started developing habits that were never part of the intended workflow. Instead of following the full decision path or escalating the right case, it begins taking shortcuts that feel locally efficient.
That creates an explainability problem. The decisions the agent is now making can't be traced back to any rule the organization deliberately set. The pattern driving them emerged from behaviour, not instruction. When a regulator or an auditor asks why a decision was made, there is no policy to point to. Just a habit the agent developed on its own.
Coordination drift is the blurring of ‘shared understanding’. This one emerges when the workflow uses more than one agent. In this, one agent may still be working from the updated policy, while another explains the outcome using an older version of the rule, and a third routes the case based on whichever threshold has remained most salient in memory.
That creates an integrity problem. No individual agent is obviously wrong, but the system as a whole has broken down, and the organization can no longer stand behind what the system produced.
Across all four forms, the root problem is the same. The agent has no durable, external source of truth it can check while making the decision. Without that layer, it is still reconstructing from memory, and memory is exactly where the degradation is happening.
Better models and bigger context windows don’t fix memory drift
When agents start producing inconsistent outputs, the natural response is to upgrade to a more capable model or expand the context window so the agent finds relevant facts faster.
However, none of these fixes addresses memory drift.
A more capable model maintains instruction consistency more reliably over long contexts, but that is not the same as solving drift. No matter how good the model gets, it is still navigating from memory, and memory will still degrade as context grows complex. In fact, a better model can be wrong more persuasively, which is a worse failure mode than being wrong obviously.
The second solution of a larger context window provides more capacity to hold information, but capacity is not the same thing as reliable recall. Research published in Lost in the Middle found that LLMs pay the least attention to information sitting in the middle of a long context. A larger context window doesn't fix that if anything, it means that the agent can now hold more versions of the same policy, but with no ability to distinguish between them.
The issue is that both these fixes treat memory drift as an information problem, which it’s clearly not. The agent isn't lacking information. Drift is an architectural problem. The architecture is lacking a durable, external source of truth where an agent can read from at any point something that doesn't live inside its compressing context window and doesn't require the agent to reconstruct from memory.
The reason enterprise AI becomes unreliable over time
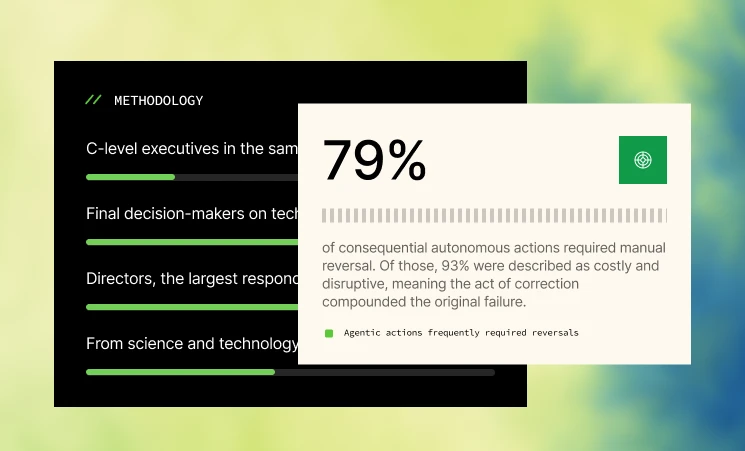
A recent research found that LLMs lose track of details progressively over long conversations, with awareness dropping by up to 39% after just 50 turns. In an enterprise deployment where an agent processes thousands of decisions continuously over months, that level of degradation curve has a direct cost attached to it.
While most enterprise AI evaluations ask the right questions, such as: Does it process at scale? Does it integrate with existing systems? Does it perform accurately in the test environment against the current policy? All great questions for Day 1.
But they don't ask what the agent will do on Day 200, after multiple policy updates, several regulatory changes, and months of continuous operation have progressively compressed its working memory.
The better question is: when the agent has been running for six months, how do you guarantee that the system respects the current truth? Does it have somewhere reliable to check what is true right now? Or is it still relying on an accumulated memory with no clear sense of what is current and what has expired?
The answer to memory drift isn’t better memory or a better model. It’s building agents that don’t have to rely on memory alone. If you want long-lived agents that don’t poison themselves with compressing memory, they need access to a source of truth they can refer to at any point during a task.
What that architecture requires is a shift from memory systems to control systems, which we’ll cover in the following blogs. For now, you can explore how text as a control plane can be a potential solution to memory drift.





