












.webp)
Every enterprise is deploying AI agents. The call queues are shrinking, the help desks are being restructured, and the pitch decks all say the same thing: faster resolution, lower costs, better customer experience, around the clock, across every channel.
But there is a problem nobody is talking about loudly enough. Most of these agents are technically functioning and functionally failing. They answer questions. They do not resolve customer issues. And the gap between those two things is costing enterprises more than they realise, in missed revenue, eroded trust, and customers who try the AI once and never come back.
In this episode of Kore.ai's AI Activations, host Cobus Greyling, Chief AI Evangalist, sits down with Kane Sims, founder of VUX World, to get into the specifics. Kane has spent over a decade helping enterprises build conversational AI that actually works, and together they cover the four areas where most deployments fall short: design, testing, omnichannel strategy, and measurement.
This article captures the key takeaways.
Watch the webinar here - Beyond containment: how to measure real impact in AI customer experience
How to design AI agents that resolve customer issues (not just answer questions)
When generative AI arrived at scale, many organizations handed the keys to their engineering teams. That was understandable: the technology was API-first, and developers had the earliest access. But a technology-first mindset tends to produce technology-first outcomes, which is not the same as customer-first outcomes.
"With AI agents, it is all about tech, and it feels like the design is seriously lagging." - Cobus Greyling, Kore.ai
It is a fair observation, and one that resonates across the industry. The word that keeps coming up when teams reflect on what is missing is not capability. It is care.
"Design is not about making it sound nice. Design is about what the purpose of the application is, how it should manifest, how it should treat customers, and what we need to do to enable the conversation to be fluid." - Kane Sims, VUX World
Consider a common telco scenario. A customer contacts an AI agent and says, "How do I upgrade my contract?" The agent searches the knowledge base, retrieves the relevant policy, and responds with a technically accurate answer: pay off your current contract and take out a new one.
The agent has answered the question. It has failed the customer. Because what that customer actually communicated is: "I am ready to give you more money for the next 24 months." A well-designed agent would recognize that signal and respond accordingly. A RAG-heavy, tech-first agent just answers the surface question and stops.
Design principle: Conversation design is not about tone of voice or word choice. It is about understanding user needs, mapping the journey from an ambiguous opening to a resolved outcome, and building the integrations, content, and logic that make that journey possible.
For enterprise buyers, the implication is direct: if your AI agent evaluation criteria focus primarily on NLP accuracy and response quality, you are measuring the wrong things. Add outcome completion to your scorecard before you sign anything.
How to test AI agents: Moving beyond accuracy to outcome-based measurement
AI evaluation is maturing rapidly. Teams are familiar with frameworks like RAGAS, assessing retrieval quality, answer relevance, groundedness, and completeness. That testing is necessary. It is not sufficient.
The gap: Single-turn, input-output testing tells you whether a response is accurate. It does not tell you whether the customer achieved what they came to do. These are different questions, and only one of them maps to business value.
Conversations are not one-shot interactions. A customer arrives with a need. That need unfolds over multiple turns, with ambiguity, clarification, and progression. Testing whether each response is accurate ignores the arc of the conversation entirely.
The right unit of measurement is the customer objective. Did the person who arrived needing to resolve a billing dispute actually resolve it? Did the customer exploring a mortgage product get to a point of meaningful progress? Did the person trying to upgrade their broadband package leave with an upgrade confirmed?
The 3 levels of AI agent testing maturity
Enterprise teams should be building toward all three levels simultaneously.
Level 1: Functional accuracy
- What it measures: Is each response relevant, accurate, grounded, and complete?
- Tools: RAGAS-style frameworks, retrieval evaluation, chunking, and prioritization assessment.
- Status: Most teams are here. This is the baseline, not the finish line.
Level 2: Conversational coherence
- What it measures: Does the agent handle multi-turn flows, ambiguity, and topic progression correctly?
- Tools: Simulated user journeys, dialogue management review, and disambiguation testing.
- Status: Most teams have not yet built this capability.
Level 3: Outcome achievement
- What it measures: Did the customer resolve their actual need? Was the experience good enough that they would use the channel again?
- Tools: Outcome-based simulation with graded resolution scoring, experience quality assessment, and cross-channel tracking where possible.
- Status: Still largely manual at most organizations. Significant automation opportunity.
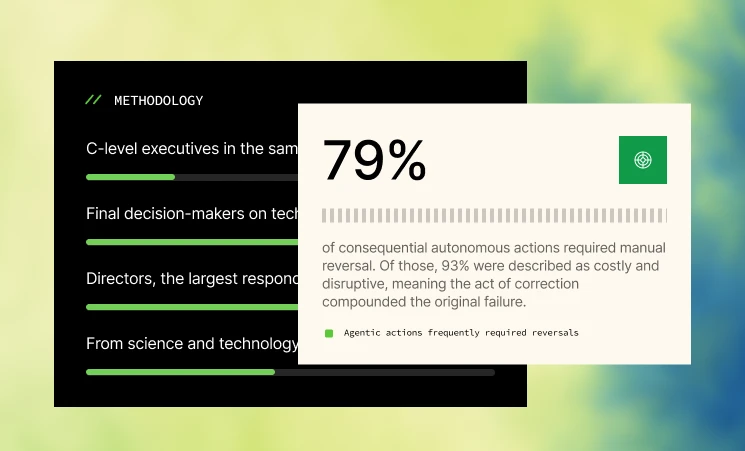
Even major institutions like NatWest were still doing outcome testing manually during their AI agent build. The teams that get ahead in the next 12 months will be those that automate level 3 testing at scale.
Omnichannel AI customer service strategy: How to route for resolution, not just presence
The promise of omnichannel was that customers could move seamlessly between any touchpoint and receive a consistent, connected experience. The reality, as most practitioners know, is that channels remain largely siloed, context rarely transfers, and the experience varies significantly depending on where a customer happens to land.
"We were supposed to go from omnichannel to ambient orchestration, where everything feels the same experience. But I get the sense that many enterprises are not there yet. It is not the same experience or the same continuity even amongst different channels." - Cobus Greyling, Kore.ai
A more pragmatic frame: rather than trying to deliver full resolution on every channel, the goal should be to meet customers where they are and route them to where they can actually get help.
"The channel surfing you mentioned is only because customers cannot get any helpful responses from anywhere. They want to get their problem solved. And the data shows that people will use whatever channel you direct them to, if you can guarantee they will get the problem solved." - Kane Sims, VUX World
Reframed omnichannel strategy:
- Be present on the channels where your customers initiate contact.
- Understand which channel delivers the best completion rate for each use case.
- Design clear, low-friction handoffs between channels when the initiating channel is not the right resolution channel.
- Track outcome across the full journey, not just within a single session.
Some constraints are hard. Debt collection over WhatsApp is against the platform's own policies. Complex mortgage discussions over voice are difficult because the information load exceeds what short-term memory can handle without a screen. Recognizing these constraints and designing around them is more valuable than chasing channel parity for its own sake.
How to measure AI agent ROI: Beyond cost containment to revenue impact
Traditional contact center metrics, like average handle time, containment rate, and first contact resolution, were designed for a human-agent world. Many of them were of limited value even then, and they become actively misleading in an AI-augmented environment.
Average handle time, for example, typically drops when AI handles simple queries. But the simple queries that AI absorbs leave only complex cases for human agents. Human AHT rises. If you are still using that metric to evaluate performance, you will draw exactly the wrong conclusion.
Cobus drew a sharp parallel here, referencing the attribution problem that plagued online advertising in its early years. When advertisers could not reliably connect ad spend to outcomes, budgets were wasted, and confidence eroded. It was only once attribution was solved that the online ad industry scaled. The same dynamic is playing out in enterprise AI right now: teams that cannot clearly connect their AI programs to business outcomes are struggling to maintain investment, while a "shadow AI economy" of unofficial tools quietly grows around them.
"Traditional contact centers have very granular measures of success. It is a highly attributed area. But how do you go beyond cost saving, beyond revenue? What is your feel about measuring success in the backdrop of this traditional contact center world?" - Cobus Greyling, Kore.ai
The customer-to-staff ratio: A more honest metric
The only metrics that ultimately matter are cost and revenue. Everything else should be traceable to one or both. Two organizations that got this right:
Landra's Hotels: Landra's was failing to answer 40% of incoming calls. Rather than measuring missed calls as a service failure, they used AI to handle all low-value queries: check-in times, pool hours, pet policies. This freed their human team to focus exclusively on booking inquiries. The contact center shifted from a cost center to a revenue center, measured not on handle time but on booking conversion.
IKEA: IKEA automated approximately 50% of voice contacts with its AI assistant, Billy. Rather than reducing headcount, they redeployed staff as interior design consultants. Customers can now call IKEA and pay for a personalized kitchen design service. The metric shifted from cost per contact to revenue per customer interaction.
The common thread: AI frees human capacity, and the organizations that win are those that redirect that capacity toward higher-value work rather than simply reducing it.
What LLMs can't do alone: Why enterprise AI agents need conversation management
This is a critical distinction for enterprise buyers evaluating platform vendors, including the large AI labs now moving into customer service.
The ability to understand and generate language is not the same as the ability to conduct a conversation. Conversation has structure: sequences, turns, progression toward a goal, and disambiguation of ambiguity. LLMs do not natively understand any of this. They are extraordinarily good at responding to inputs. They are not natively good at managing the arc of a customer interaction.
The practical symptom of this is what the session called the "full stop problem." A customer says something ambiguous. The AI, eager to be helpful, retrieves an answer and delivers it. The customer's actual need remains unresolved because no one asked the right clarifying question first.
A simple banking example illustrates this well. A customer asks: "What is the limit on my Apple Pay?" There are multiple possible reasons for that question. The customer may have hit their limit and be frustrated. They may want to increase it. They may be comparing it against another payment method before making a purchase. Each of these requires a different response. An LLM given free rein will answer the surface question. A well-designed agent will ask why before answering.
What this means for your vendor evaluation: Ask specifically how the platform handles intent disambiguation, multi-turn goal progression, and out-of-domain detection. Platforms that hand you powerful LLM capabilities without a conversation management framework are giving you an engine without a transmission.
Customer intent mapping for AI agents: Why it still matters in the LLM era
There was a period when practitioners declared that "intents are dead" because LLMs could handle open-ended dialogue without explicit intent classification. The conversation pushed back on this clearly.
What changed was the technical mechanism for capturing intent. The machine learning classifiers that mapped utterances to labeled intents in the NLU era became unnecessary when LLMs could understand language more broadly. But the underlying concept, that every customer contact represents a need that must be understood before it can be addressed, did not go anywhere.
"Intent never left. What was left was the machine learning architecture of classifying a customer utterance based on a model that you would call an intent. A customer intent always exists. It is the substitute for a customer need." - Kane Sims, VUX World
Before designing any AI agent, map your customer intents. Analyze call data, chat logs, and email queues to understand where demand actually sits. Then build and test against those specific needs. The scope of what any business's customers actually need is finite: they are looking for a product, buying it, waiting for it, trying to use it, or leaving. Design against that reality, not against an imagined open-ended conversation that covers everything.
What to prioritize in the next 12 months
Most organizations are not close to realizing the full potential of the technology available to them today. The constraint is not the technology; it is the frameworks, testing practices, and design discipline surrounding it.
1. Invest in outcome-based testing infrastructure.
Manual testing of conversation quality does not scale. Invest in tooling that simulates real user journeys, grades resolution success, and assesses experience quality automatically. This is where most teams will make the biggest practical gain in the near term.
2. Bring design back into the room.
This does not mean hiring more UX writers. It means ensuring that someone on your AI agent team is accountable for the full stack of conversation quality: intent coverage, dialogue management, disambiguation, escalation logic, and the integration layer that enables resolution. That is a distinct role from engineering, and it needs a seat at the table.
3. Tie everything to cost or revenue.
Vanity metrics will not survive the next budget cycle. Every AI initiative should have a clear line to either cost reduction or revenue generation. The organizations making the strongest case for continued AI investment are the ones that have restructured their measurement framework around business outcomes rather than interaction statistics.
"You have everything you need today. The thing I absolutely see becoming critical is testing and design balance. There is no dispute that you need a strong technical team. But someone needs to be caring about the end-user experience. Not just the words. Everything involved in the whole stack to make what is said the perfect thing to achieve the user goal." - Kane Sims, VUX World
Key buyer takeaways
- Evaluate for outcome, not accuracy: Add outcome completion rate to your AI vendor scorecard. Response accuracy alone does not predict business value.
- Test the whole conversation: Single-turn testing is necessary but not sufficient. Demand outcome-level testing capability from your platform and partners.
- Reframe your channel strategy: Stop trying to resolve everything on every channel. Focus on presence plus triage. Route customers to where they can get resolved.
- Retire legacy metrics now: Average handle time and containment rate will mislead you in an AI environment. Build measurement around cost and revenue impact.
- Ask vendors about conversation management: LLMs understand language. Conversation management is a separate capability. Make sure your platform has both.
- Start with intent mapping: Before designing any agent, analyze your call and chat data to map real customer needs. Scope is your friend.
CTA: Webinar - https://www.kore.ai/webinar/beyond-containment-how-to-measure-real-impact-in-ai-customer-experience
FAQs
Q1. What is the difference between an AI agent and a traditional chatbot?
A traditional chatbot follows rigid decision trees or intent classifiers to route conversations toward predefined answers. An AI agent uses large language models to understand natural language more flexibly, handle ambiguity, and take actions through system integrations. The key practical difference is that AI agents can handle far more variation in how customers phrase things. However, as this session makes clear, flexible language understanding does not automatically translate into good conversation management or reliable outcome achievement. That still requires deliberate design.
Q2. What metrics should replace average handle time and containment rate?
The metrics that matter are those traceable to cost or revenue. On the cost side: reduction in human escalation volume, automation rate on specific use case categories, and operational cost per resolved interaction. On the revenue side: booking or conversion rate where AI handles pre-sales queries, customer lifetime value trends, and churn reduction. The customer-to-staff ratio is a useful long-term indicator of how efficiently AI is scaling your service capacity relative to your customer base.
Q3. Does omnichannel mean you need to resolve everything on every channel?
No, and trying to do so is one of the most common strategic mistakes in enterprise CX. The goal of omnichannel should be presence plus intelligent triage, not universal resolution. Customers need to be able to reach you on their preferred channel. Once contact is made, the system should be able to assess whether that channel is the right place to address the specific need, and, if not, route them clearly to a channel where resolution is possible. Customers will follow that routing if they trust it leads to a solution.
Q4. Are customer intents still relevant in the era of generative AI?
Yes. What changed is the technical mechanism, not the concept. NLU-era systems classified utterances against labeled intent models. LLMs handle a much wider range of phrasing without explicit classification. But the underlying truth remains: every customer contact is an expression of a need, and that need must be understood before it can be addressed. Intent mapping, the practice of analyzing contact data to identify what customers actually need from your business, is still the right starting point for any AI agent design. The architecture underneath has changed; the design discipline has not.
Q5. How should enterprise teams approach AI agent testing right now?
Build toward three levels simultaneously. Start with functional accuracy testing using frameworks like RAGAS to validate individual responses. Add conversational coherence testing to ensure multi-turn flows, disambiguation, and topic progression work correctly. Then invest in outcome-level testing that simulates full user journeys and grades whether the customer's objective was actually achieved. Most teams are strong at level one, inconsistent at level two, and doing level three manually if at all. Automating level three is the highest-leverage testing investment available right now.






