












.webp)
A Chain-of-Thought is only as strong as its weakest link; a recent study from Google Research created a benchmark for Verifiers of Reasoning Chains
Introduction
There has been a significant number of studies performed on the topic of automated verification of LLM interactions. These methods evaluate LLM output and reasoning steps to evaluate and improve the correctness of responses.
In this study from Google Research, there is an observation that no fine-grained step-level datasets are available for the evaluation of chain-of-thought.
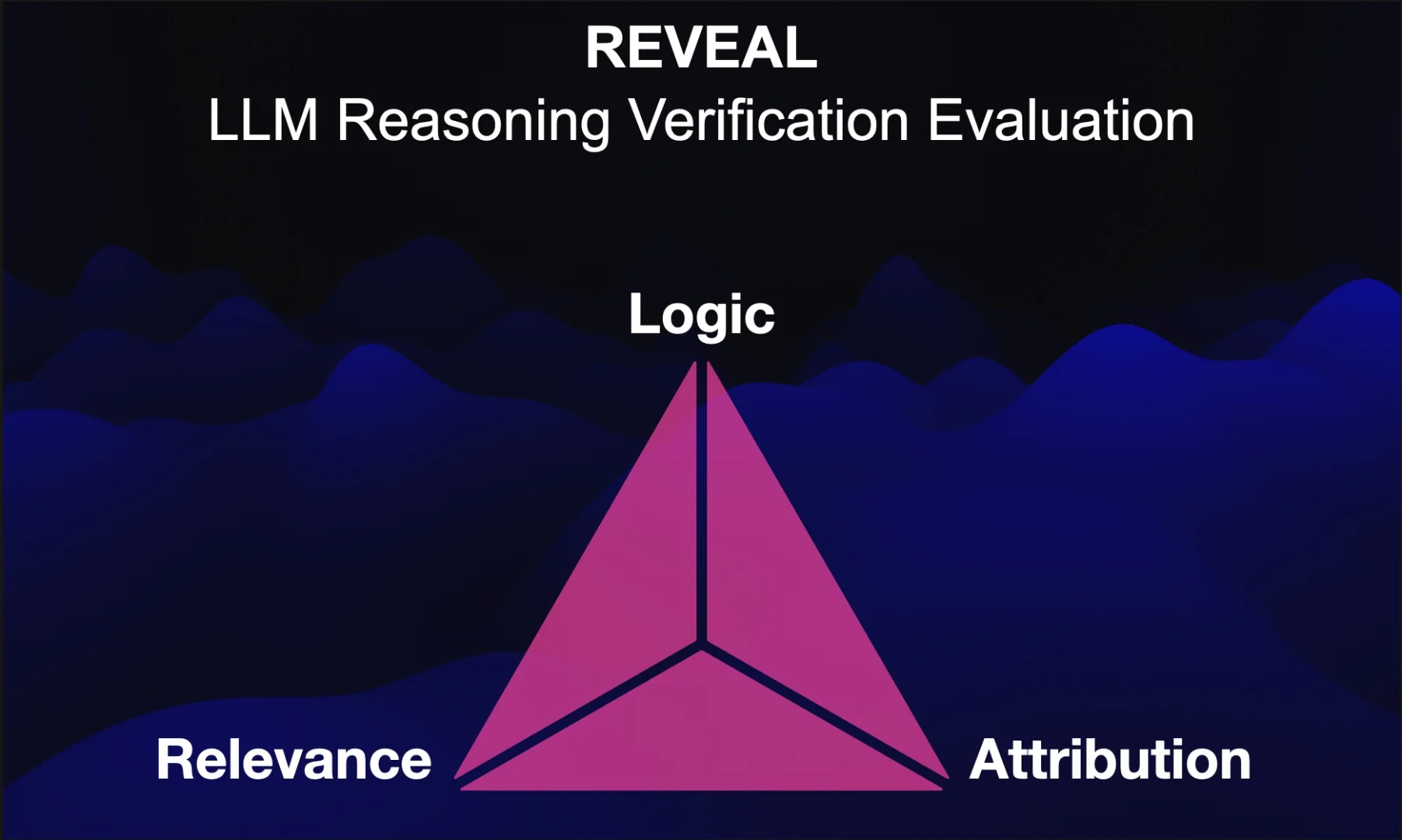
Hence the introduction of REVEAL, which is in essence a dataset to benchmark automatic verifiers of complex CoT for open-domain question answering.
REVEAL contains comprehensive labels for:
- Relevance,
- Attribution to evidence passages, and
- Logical correctness
of each reasoning step in a language model’s answer, across a wide variety of datasets and state-of-the-art language models.
The resulting dataset, named REVEAL, serves as a benchmark for evaluating the performance of automatic verifiers of LM reasoning.

Challenges
The research primarily focuses on evaluating verifiers that assess evidence attribution to a given source, rather than fact-checkers that perform evidence retrieval themselves.
Due to this focus, REVEAL can only assess verifiers that operate on specific provided evidence.
Some knowledge claims labelled as “unsupported” in the dataset may have supporting or contradictory evidence that was not surfaced by the retriever.
However, it’s important to note that the dataset aims to gather a diverse range of cases to evaluate verifiers, rather than to assess the CoT itself using an “ideal” retriever. The labels in the dataset are well-defined for the specific evidence passages used.
Practical examples
REVEAL is an evaluation benchmark for verifying reasoning chains in a Chain-of-Thought format. REVEAL checks whether a reasoning chain is a correct justification to the final answer.
What is important to note, is that the answer can be correct even when the reasoning is incorrect.

The image above shows four verifiers in the middle column which verifies the correctness of a Chain-of-Thought on the left. The dataset is used to benchmark multiple verifiers, with the result shown on the right.
Below, a flowchart of the protocol for verifying reasoning and correctness step-by-step.

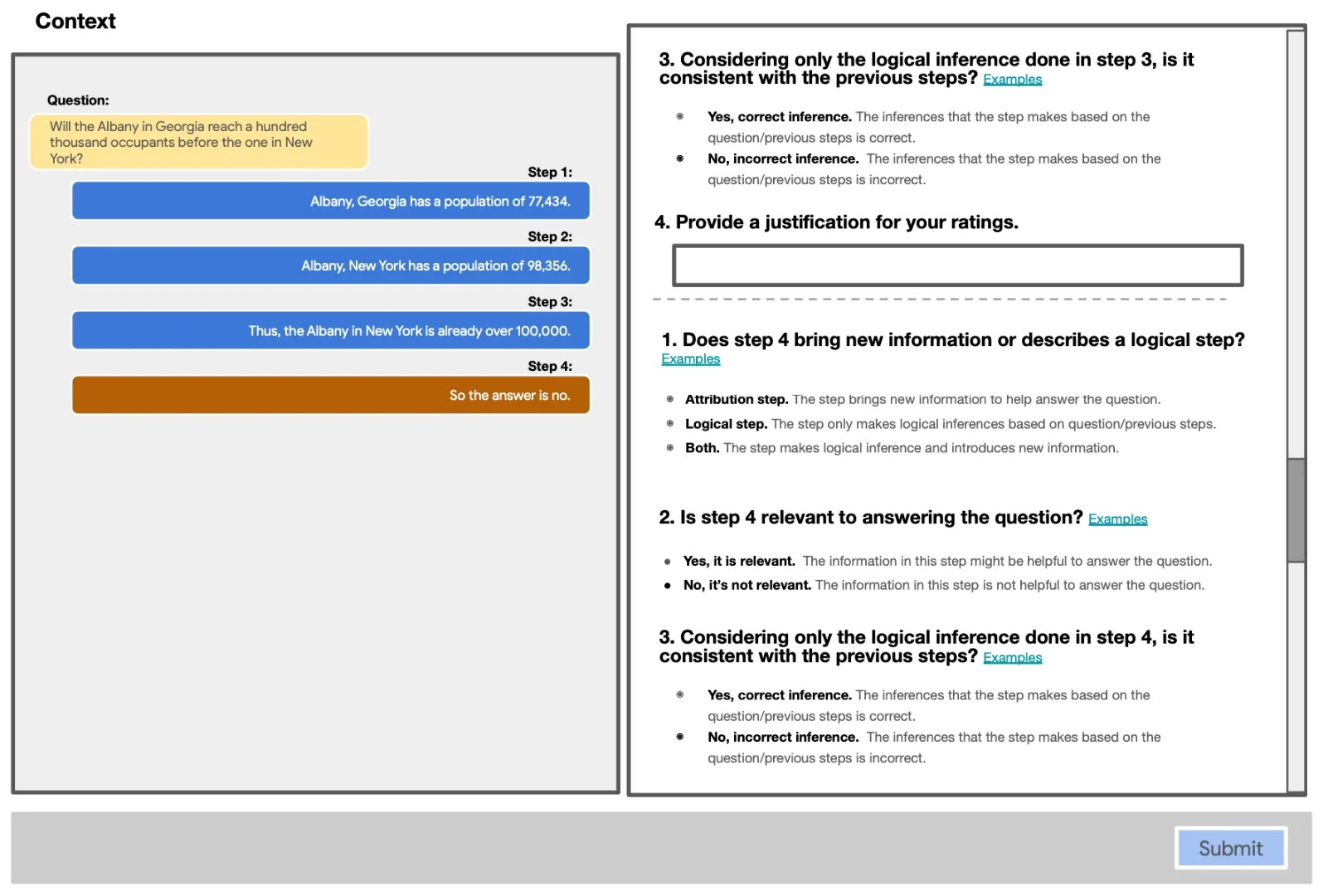
Considering the image below, a REVEAL instance is shown with labels for each step, for step type, relevance and correctness.

Annotation
As seen below, annotation was performed via a complex GUI and relies heavily on the annotators judgement. The annotation task is split into two tasks; one task was focused on the logic annotation (including relevance, step type and logical correctness ratings). Together with another task focused on the attribution annotations(including relevance and step-evidence attribution). In the image below the annotation interface for the attribution task is shown.

And in the image below, the annotation GUI is shown for the task of annotating the logic.
Consideration
Something I find interesting from this study is the complexity involved in creating highly granular datasets. A second consideration is the level of data design involved, considering the complex data structure. The GUI for data annotation is also complex and I’m quite sure it demanded a high level of expertise from the annotators. It is evident that the process is time consuming, demanding a more complex annotation framework. This contributes to a higher cost of annotation





