












.webp)
Enterprise AI agents are making thousands of decisions every day inside your organization: routing customer cases, evaluating loan applications, resolving support tickets, flagging compliance exceptions. Most enterprise platforms log the input and the output. Almost none of them capture the thought process or the decisions?
When an AI agent produces a wrong decision, an incorrect escalation, or a policy violation, the organizations operating those agents typically cannot reconstruct why it happened. They cannot identify which guardrail failed, which policy expression evaluated incorrectly, or which tool invocation returned unexpected data. They can see the results but cannot trace the decision path that produced it.
This is the enterprise AI observability gap: the difference between knowing what your AI did and being able to explain why it did it. It has direct consequences for engineering teams who cannot debug what they cannot see, for compliance teams who cannot produce defensible audit trails, and for leadership teams who cannot confidently answer their AI-drive decisions
What is AI observability and why do most enterprise AI platforms get it wrong?
The word AI observability borrows its meaning from software engineering, where it means the ability to understand the internal state of a system purely from its external outputs. A well-instrumented application tells you not just that something broke, but what state the system was in when it broke, why it made the decisions it made, and what path it took to get there.
In the front-end world, this is table stakes. Sentry captures breadcrumbs. React Dev-Tools traces component trees. Segment logs user events. Performance profiling records timing to the millisecond. When a bug surfaces, you have a complete forensic record: what happened, in what order, and why.
Enterprise AI observability should operate with the same level of traceability but in practice, it rarely does.
Most organizations deploying AI agents today are running with what might be called "output logging": capturing the final response an agent produced, perhaps the initial query that triggered it, and little else in between. They track inputs and outputs, and they call the middle "the model."
That is not observability. It is output logging without visibility into the operational decisions that produced the outcome.
How many decisions does an AI agent make per interaction and what actually gets logged?
To understand why the gap matters, you first have to understand what actually happens inside a single agent interaction in any production-grade AI deployment.
When an enterprise AI agent processes a customer escalation, a support ticket, a loan application, or a claims query, it doesn't make a single decision. It makes a cascade of them, each depending on the last:
- Intent resolution: What is the user actually asking? Which domain, which workflow, which policy applies?
- Context retrieval: What information does the agent need to gather from memory, from knowledge bases, from integrated systems?
- Tool selection and invocation: Which external systems should be called, in what order, with what parameters?
- Guardrail evaluation: Does this response violate any compliance policies? Is it within the scope of what this agent is authorized to say?
- Policy and expression checks: Are there conditional rules that govern this specific situation? CEL expressions, business logic layers, permission tiers?
- Handoff determination: Should this be escalated to a human agent? Routed to a specialist? Closed autonomously?
- Response generation and completion detection: What should the final output be, and how does the system know when the task is complete?
A single agent turn (one exchange, one decision) generates between eight and fifteen meaningful trace events across these layers.
Most enterprise observability setups capture one or two of them.
When something goes wrong, the organization can only see about 15% of how that decision got made. Everything else vanishes the moment the interaction ends, with no way to go back and look at it.
What happens to your business when your AI platform has poor observability
The enterprise AI observability gap operates on two distinct levels, and understanding both is essential to appreciating why this is not a logging problem you can solve with a better dashboard.
Engineering teams cannot debug AI agent failures without full decision logs
At the engineering level, the gap creates a set of failure modes that compound over time.
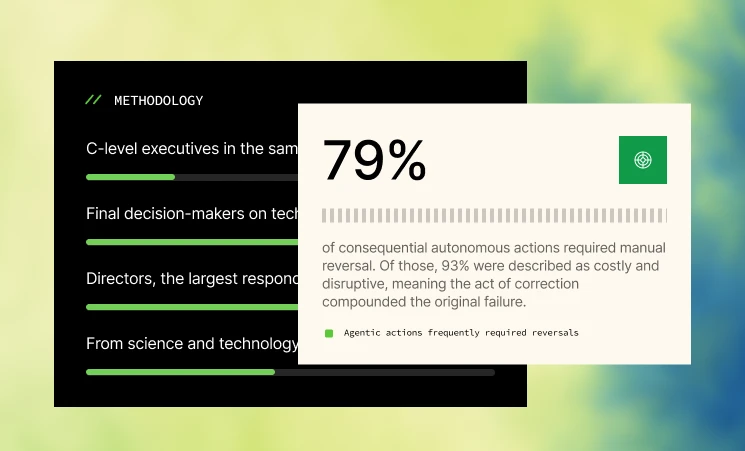
When an agent makes a wrong handoff decision (escalating a case it should have resolved, or resolving a case it should have escalated) you cannot trace it back to the CEL expression that evaluated incorrectly if you never captured that evaluation.
When an agent violates a guardrail in a subtle way, producing a response that is technically within policy but operationally inappropriate, you cannot retrain or reconfigure without understanding the exact path the agent took. When a tool invocation produces unexpected results, you cannot root-cause the issue if the invocation itself was not logged with its parameters and return values.
This creates a feedback loop that systematically degrades agent quality over time. Problems are visible at the output level (wrong answers, incorrect routing, policy violations) but invisible at the causal level. Teams optimize symptoms rather than root causes , adjust prompts rather than policies, and accumulate technical debt in their AI operations without a reliable diagnostic path to resolve it.
The organizations winning in production AI are not necessarily using more sophisticated models. They are using better instrumentation. They can see the full trace of every agent turn, correlate outcomes with the specific decisions that produced them, and continuously improve their systems based on evidence rather than inference.
The AI decided" is not an acceptable answer for regulators, boards, or customers
At the leadership and regulatory level, the stakes are higher. Observability failures become accountability failures.
Enterprise AI is no longer operating in sandboxed experimentation environments. It is making decisions that affect customers, employees, partners, and regulators. It is declining loan applications, resolving insurance claims, routing support cases, and generating communications that carry organizational liability.
When those decisions are wrong (and at scale, some will be) the organizations facing the consequences will need to explain what happened. Not to their engineering team. To regulators who are increasingly mandating AI accountability frameworks. To customers who believe they were treated unfairly. To boards that want to understand what their AI exposure is. To auditors who are building compliance programs around AI governance.
"The model decided" is not an explanation that any of these audiences will accept. It is, in fact, likely to make the situation significantly worse, because it implies that the organization deployed decision-making systems it does not understand, over which it has no governance, and for which it cannot demonstrate control.
The legal and regulatory environment is moving quickly in this direction. The EU AI Act explicitly requires high-risk AI systems to maintain logs sufficient to enable post-hoc review and human oversight. Financial services regulators in multiple jurisdictions are developing guidance on AI explainability requirements. Data protection frameworks are increasingly incorporating rights to explanation for automated decisions. The question is not whether accountability requirements will arrive. It is whether your current infrastructure can meet them.
Why weren't enterprise AI platforms built with observability from the start?
It would be unfair to suggest that the enterprise AI observability gap is the result of negligence. It emerged from a set of conditions that were understandable at the time, but which the current maturity of enterprise AI has left behind.
- First-generation AI deployment culture prioritized speed over governance.
The early enterprise AI platforms were built to demonstrate what was possible, not to govern it. Observability was considered a "phase two" concern, something to bolt on after the initial deployment proved its value. Many organizations are still waiting for phase two.
- AI observability tooling was built for developers iterating on models, not operations teams governing them.
Existing observability solutions in the AI space (LLM tracing tools, evaluation frameworks, prompt management platforms) were designed to help developers iterate on models. They capture LLM invocations with reasonable fidelity. They capture almost nothing about the orchestration layer: the guardrails, the tool resolutions, the policy checks, the handoff logic. Yet it is the orchestration layer where most operational failures originate.
- Traditional software logging patterns do not map to how AI agents actually make decisions.
Traditional application observability is built around the idea that you can log events discretely: a function called here, a database queried there. Agent interactions are not like that. They are non-deterministic, multi-step, contextually dependent processes where the significance of any single event is inseparable from the sequence that produced it. Applying traditional logging patterns to agent systems produces a record that is technically complete but operationally meaningless.
- The absence of observability rarely becomes visible until an incident exposes it
Until something goes wrong, the absence of observability is invisible. Organizations can run agents for months without a visible incident, and conclude that their existing instrumentation is adequate. The gap only reveals itself at the worst possible moment: during an incident, when the absence of an operational trace is the problem.
What does good AI observability look like and what should your platform be able to do?
The organizations that have solved the enterprise AI visibility problem (and there are still few of them) share a common architectural principle: observability is designed into the execution model, not layered over it afterward.
Bolt-on observability can capture what an agent outputs. It cannot capture why it made the decisions that produced that output, because those decisions happen inside the execution engine in ways that external logging cannot reach. The trace events that matter (guardrail evaluations, CEL expression results, policy checks, handoff logic) are only capturable if the execution engine is built to emit them.
What this looks like in practice:
- Full-trace capture at every AI decision layer, not just inputs and outputs.
Every meaningful event in the agent turn is emitted as a structured trace event: intent resolved, context retrieved, tool invoked (with parameters), guardrail evaluated (with result and reason), policy check performed, handoff decision made, completion detected. This is not the same as logging everything. It is logging the right things, at the right level of granularity, with the right structure to enable downstream analysis.
- Causal lineage that shows why each AI decision was made, not just that it occurred.
A trace is not just a list of events. It is a causal graph. Event B happened because Event A produced outcome X. The guardrail fired because the policy expression evaluated to true given the retrieved context. The handoff occurred because the confidence score fell below the configured threshold for that intent category. Understanding causality is what transforms logs from a forensic archive into an operational tool.
- Real-time AI monitoring that surfaces leading indicators before failures reach the output level.
Most AI monitoring setups alert on output anomalies (response quality scores, latency spikes, error rates). Operational observability alerts on upstream indicators: guardrail evaluation rates trending upward before a policy violation occurs, handoff decision confidence distributions shifting before human escalation volumes rise, tool invocation error rates climbing before they produce visible failures at the output level.
- Governance-ready AI audit trails structured to answer regulator and legal questions, not just internal ones.
The format and completeness of observability data matters as much as its existence. A governance-ready audit trail is structured to answer the specific questions regulators, auditors, and legal counsel will ask: What was the agent authorized to do in this context? What guardrails were in place? What was the output, and what decision path produced it? Can you demonstrate that the system operated within its defined parameters? These questions require a level of data structure and completeness that general-purpose logging rarely achieves by default.
Why is AI accountability now a board-level concern and not just an IT problem?
There is a larger pattern at work here that goes beyond technical architecture.
The first phase of deployment (experimentation, proof-of-concept, internal tooling) tolerated a certain amount of opacity because the stakes were relatively low and the primary goal was demonstrating capability. That phase is over for most large enterprises.
The second phase (customer-facing operations, regulated workflows, high-stakes decision-making) requires something different: not just capability, but accountability. The ability to stand behind what your AI decided, to explain it to anyone who asks, and to demonstrate that it operated within the boundaries you set.
Accountability is not a feature you add to an AI system. It is a design principle, one that has to be built into the platform from the ground up, or one that will be absent when accountability is tested under real operational conditions.
The organizations that are winning in production AI today are not necessarily those with access to the most capable models. They are those that have built the infrastructure to govern what those models do: to see every decision, trace every path, and stand behind every outcome.
They have solved the enterprise AI observability gap before it became a crisis. And that infrastructure (the ability to see, to explain, to govern) is increasingly becoming the competitive differentiator in enterprise AI, especially in regulated and high-trust environments.
9 questions to audit your organization's enterprise AI observability and governance readiness
If you are responsible for enterprise AI deployment in your organization, the following questions will tell you where you stand:
On AI observability:
- For a given agent interaction that produced a wrong outcome yesterday, can you reconstruct the full decision path that led to it today?
- What percentage of the meaningful events in an agent turn are you currently capturing? (Hint: if your answer is "all of them," verify against the decision layers outlined earlier. )
- Can you correlate a specific guardrail evaluation with the output it influenced?
On AI governance and regulatory readiness:
- If a regulator asked you to demonstrate that your AI system operated within its defined parameters for a specific interaction six months ago, what would you show them?
- Who in your organization owns the answer to "what did our AI decide and why?" Is that person equipped to answer it?
- What is your current process for identifying when an agent's behavior has drifted from its intended design?
On AI platform architecture:
- Is your current observability solution built into your execution engine, or layered over it?
- Can you distinguish between trace events that occurred (what happened) and the causal relationships between them (why it happened)?
- Is your audit trail structured for operational use, or is it a raw log that would require significant processing to be useful in an accountability context?
If any of these questions expose a gap (and for most organizations, several of them will) the time to close it is before the incident that makes the gap visible.
How enterprise AI platform buying criteria are shifting from agent capability to agent accountability
The AI platforms of the next generation will be defined not just by what they can do, but by what they can explain. The competitive landscape in enterprise AI is shifting from "which platform gives me the most capable agents" to "which platform gives me agents I can deploy with confidence, govern with rigor, and stand behind when it matters."
That shift is already underway. Regulatory requirements are moving from guidance to enforcement. Customer expectations around AI transparency are hardening. Board-level scrutiny of AI risk is intensifying. The organizations that have invested in operational transparency, that have built or adopted platforms designed for accountability from the ground up, are finding that this infrastructure is not just a governance requirement but a genuine competitive advantage.
It accelerates deployment because it reduces the risk that stops deployment. It builds trust with customers because it enables demonstrated accountability rather than asserted accountability. It creates defensibility in regulated markets that competitors without equivalent infrastructure simply cannot match.
The enterprise AI observability gap is real, it is widespread, and it is increasingly consequential. The organizations that close it proactively will be the ones that define what enterprise AI looks like in the next phase of its maturity.
The question is not whether you need operational transparency. The question is whether you will build it before you need it, or after.
Kore.ai builds enterprise AI infrastructure for organizations that need to deploy agents they can stand behind. If you're evaluating what operational transparency looks like in practice, we'd like to show you what's coming.






