Search across silos. Automate workflows. Orchestrate AI agents. Govern with confidence.
Leverage Agentic capabilities to empower customers and create personalized experiences.
Streamline knowledge-intensive business processes with autonomous AI agents.
.webp)

Join Kore.ai’s re:imagine Tour in Dallas on 16th October, 2025. Discover how enterprises are scaling AI with real use cases and expert insights.
Join Kore.ai’s re:imagine Tour in Dallas on 16th October, 2025. Discover how enterprises are scaling AI with real use cases and expert insights.
.webp)
What is RAG - Retrieval-Augmented Generation ?
The paradigm of information retrieval is undergoing a profound transformation with the advent of Retrieval-Augmented Generation (RAG). By harmonizing the precision of advanced search methodologies with the generative power of AI, RAG transcends the constraints of traditional search engines and standalone language models. This comprehensive guide delves into the mechanics, applications, and transformative potential of RAG, redefining how enterprises search and utilize knowledge.
Table of Contents [Show]
- The Evolution of Information Retrieval
- What Exactly is Retrieval-Augmented Generation (RAG)?
- Key Steps in RAG
- Main Concepts of RAG
- How does RAG differ from traditional keyword-based search?
- Why Do We Need RAG?
- Types of RAG
- Key Benefits of RAG
- The Kore.ai Approach: Transforming Enterprise Search with AI Innovation
- Kore.ai Platform : Advanced RAG - Extraction and Indexing
- Kore.ai Platform : Advanced RAG - Retrieval and Generation
- AI for Work Case studies
- The Promising Future of RAG
The evolution of information retrieval
Not long ago, finding the right information was a slow and manual process. In 2021, even the most advanced search engines required users to type keywords, sift through long lists of links, and piece together answers from multiple sources. It worked, but it often felt like searching for a needle in a haystack, especially when the question was complex or context-specific. Then came 2022 and the arrival of ChatGPT. Suddenly, the paradigm shifted. Instead of scrolling through endless search results, users could ask a question and receive a clear, conversational answer almost instantly. It felt like a leap forward: information retrieval became faster, more accessible, and more intuitive.
Yet, as powerful as large language models (LLMs) like ChatGPT are, they come with clear limitations. They can only generate answers based on the data they were trained on, which means they sometimes lack up-to-the-minute accuracy, enterprise-specific knowledge, or deep contextual relevance. For business leaders who need answers grounded in their own organizational data, this gap becomes a critical challenge.
This is exactly where Retrieval-Augmented Generation (RAG) enters the picture. RAG combines the precision of traditional search with the intelligence of generative AI, bridging the gap between raw retrieval and meaningful, context-rich answers. Instead of relying solely on what a model has memorized, RAG dynamically pulls in enterprise data, verifies it, and generates responses that are both trustworthy and actionable.
Think of it as upgrading from a static road map to a real-time GPS. A map shows you where the roads are, but a GPS guides you along the best route, adapts when conditions change, and ensures you reach your destination faster. This evolution, from keyword search, to generative AI, to RAG, and now toward Agentic RAG, marks the beginning of a new era in Enterprise Search and Knowledge management. It is no longer about simply finding information; it is about retrieving the right data, generating contextual insights, and enabling faster, more confident decisions.
What exactly is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a framework that combines the power of information retrieval with the generative capabilities of large language models (LLMs). In simple terms, RAG enhances an LLM by allowing it to pull in relevant, up-to-date information from external knowledge sources, such as enterprise databases, documents, or other repositories, before generating a response. This means that instead of relying solely on what the model was trained on, RAG grounds its answers in authoritative, real-time data. The result is output that is more accurate, contextually relevant, and trustworthy.
Working of Retrieval Augmented Generation (RAG)

RAG systems thrive through three fundamental processes: fetching pertinent data, enriching it with accurate information, and producing responses that are highly contextual and precisely aligned with specific queries. This methodology ensures that their outputs are not only accurate and current but also customized, thereby enhancing their effectiveness and reliability across diverse applications.
Key steps in RAG:
1. Retrieval: Finding the right data
The first step in RAG is retrieval, which involves scanning a wide range of knowledge sources to identify information that best matches the user’s query. These sources can include structured databases such as CRM tables, unstructured documents like policy manuals or research reports, APIs that provide real-time data feeds, or even external sources such as the web.
Unlike traditional keyword search engines, which simply match exact words, RAG systems use semantic search and vector-based retrieval. Semantic search captures the meaning of a query rather than just its literal terms, while vector retrieval represents both queries and documents as mathematical embeddings, enabling the system to measure similarity based on context.
For example, if a user asks, “What were the main drivers of Q4 revenue growth?”, a keyword search might return hundreds of files containing the words “revenue” and “growth.” A RAG system, by contrast, can locate the specific sections of quarterly business reports or marketing summaries that directly explain the growth drivers.
This ensures that only the most relevant and context-rich information is passed forward, laying the foundation for accurate and meaningful answers.
2. Augmentation: Enriching the query
The second step is augmentation, where the retrieved information is combined with the original query to form an enriched prompt for the large language model (LLM). This step is critical because generative AI on its own can sometimes produce responses that are fluent but inaccurate, a problem known as hallucination.
By grounding the model in real-time, trusted enterprise data, RAG ensures that answers are fact-based and verifiable. Augmentation essentially bridges the gap between what the model knows (its pre-trained knowledge) and what the enterprise needs (current, domain-specific information).
For example, when asked about “customer churn trends,” the system does not rely only on the model’s general knowledge of churn. It augments the query with retrieved data from the company’s CRM, recent support tickets, and survey results. The LLM then processes this combined context to generate an answer that is both accurate and highly relevant to the organization.
This step ensures that the generated responses are not only linguistically coherent but also aligned with the latest enterprise data and context.
3. Generation: Delivering contextual answers
The final step is generation, where the LLM synthesizes the enriched prompt into a coherent, human-like response. Unlike traditional retrieval systems that only return links or document excerpts, RAG delivers natural-language answers that are directly tailored to the user’s intent.
The model draws upon the retrieved knowledge to produce contextually aware responses that often go beyond a single fact. For example, in response to a question like, “How are our European marketing campaigns performing?”, the system might generate:
“European campaigns delivered a 15% increase in lead generation this quarter. Germany and France showed the strongest performance due to localized messaging and influencer collaborations. Social media engagement also increased by 25%. Would you like a breakdown by channel or country?”
This synthesis highlights the true strength of RAG: not only delivering the right information but also presenting it in a way that is actionable, conversational, and role-specific.
Why This Matters
Together, retrieval, augmentation, and generation create a feedback loop that transforms enterprise search from a static lookup tool into an intelligent knowledge system. Employees no longer waste time sifting through irrelevant documents, and executives receive responses that are both decision-ready and contextually grounded.
For enterprises, this means faster time-to-insight, higher trust in AI outputs, and the ability to scale knowledge access across teams, departments, and roles with precision.
What are the main concepts of RAG?
RAG leverages several advanced techniques to enhance the capabilities of language models, making them more adept at handling complex queries and generating informed responses. Here's an overview:
1. Sequential conditioning
Sequential conditioning means that RAG does not generate answers solely from the user’s query. Instead, it conditions the response on both the query and the context retrieved from relevant documents. This makes the answer richer, more accurate, and context-aware.
Example - A user asks about renewable energy trends. The system retrieves the latest energy reports and conditions the output on this information, resulting in an answer that blends general AI knowledge with current data.
2. Dense retrieval
Dense retrieval converts queries and documents into vector embeddings, which represent meaning rather than just keywords. The system then measures similarity between these embeddings to retrieve the most semantically relevant content.
Example: A user searches for “AI in healthcare.” Even if the documents only mention “predictive analytics in hospitals,” dense retrieval recognizes the semantic similarity and retrieves them.
3. Marginalization
Instead of relying on a single source, marginalization aggregates insights from multiple retrieved documents. By blending perspectives, the system produces answers that are more nuanced and less biased.
Example: For a query on remote work productivity, RAG pulls from HR surveys, academic research, and technology adoption reports, then synthesizes a balanced response.
4. Chunking
Large documents are broken into smaller, manageable sections or “chunks.” This makes retrieval more efficient and ensures that only the most relevant parts of a document are used for generating responses.
Example: A compliance officer queries about data privacy. RAG retrieves only the specific section of a 200-page regulation document that addresses GDPR, rather than overwhelming the model with the entire text.
5. Semantic search
Semantic search is a retrieval technique that focuses on understanding the meaning and intent behind a query rather than matching exact keywords. It works by representing both queries and documents as vector embeddings, which capture contextual relationships between terms. This allows the system to identify and retrieve content that is conceptually relevant, even if the wording differs.
Example: A user asks, “How can we reduce customer churn?” A traditional keyword system might only return documents containing the exact word “churn.” A semantic search system, however, also retrieves resources on “customer retention strategies” and “loyalty program improvements,” since it understands the concepts are related.
6. Contextual relevance
RAG ensures that retrieved knowledge is not only correct but also tailored to the user’s intent. The system interprets context to provide answers that are aligned with the specific scenario.
Example: When asked about “investment strategies during a downturn,” RAG provides strategies based on the current market climate, not generic investment theory.
7. Hybrid retrieval
Hybrid retrieval combines dense retrieval (semantic, vector-based) with sparse retrieval (keyword or BM25-based). This ensures the system captures both meaning and exact matches for maximum precision.
Example: A user asks about “cloud migration costs.” Hybrid retrieval finds documents with exact phrases like “cloud migration” while also surfacing content about “moving workloads to the cloud.
8. Multi-Hop retrieval
Some queries require connecting information across multiple documents. Multi-hop retrieval chains together pieces of evidence from different sources to form a complete response.
Example: For the question, “Which new regulations affect our European operations in 2024, and how do they impact compliance costs?” the system retrieves regulatory documents and financial reports, then connects them to generate a holistic answer.
These principles collectively enhance the effectiveness of language models, making RAG a crucial tool for generating high-quality, contextually appropriate responses across a wide range of applications.
How does RAG differ from traditional keyword-based search?
Traditional keyword-based search relies on matching exact words or phrases from a query against documents in a database. While this method can return results quickly, it often produces static lists of links or FAQs, leaving the user to sort through irrelevant, outdated, or incomplete information. Keyword search lacks true contextual understanding, which makes it poorly suited for domains where precision, nuance, and up-to-date knowledge are critical.
Retrieval-Augmented Generation (RAG), on the other hand, represents a major leap forward. Instead of simply matching words, RAG uses semantic search and vector retrieval to understand the meaning behind a query. It dynamically fetches the most relevant and current information from diverse knowledge sources, whether internal enterprise systems, unstructured documents, or external research, and then augments that information with generative AI to deliver clear, contextual, and decision-ready answers.
Example 1: Healthcare
A keyword search for “new cancer treatments” might return a list of articles, many of them outdated. RAG can retrieve the latest clinical trial results, emerging therapies, and updated treatment protocols, then synthesize them into a precise summary tailored to the query. This helps healthcare professionals make faster, evidence-based decisions.
Example 2: Finance
In fast-moving markets, keyword searches for “Q1 financial outlook” could surface hundreds of scattered reports. RAG goes further: it retrieves current economic data, analyst insights, and real-time market trends, then generates a concise answer that highlights risks, opportunities, and actionable insights for decision-makers.
In essence, RAG bridges the gap between static search and dynamic knowledge access. It transforms search from a static repository of information into a proactive Knowledge AI system that continuously adapts, learns, and delivers responses that are not just correct but also timely, relevant, and aligned with user intent.
Read More: Retrieval-Augmented Generation (RAG) vs LLM Fine-Tuning
Why do we need RAG?
Large Language Models (LLMs) are at the core of today’s AI ecosystem, powering chatbots, digital assistants, and enterprise applications. They excel at generating natural, human-like responses by drawing from vast pools of training data. However, LLMs face serious limitations when deployed in real-world business contexts:
- Incorrect Information: When they lack the right knowledge, LLMs may “hallucinate,” generating confident but false responses.
- Outdated Content: Since training data is static and tied to a cut-off date, responses may reflect old or irrelevant information.
- Unreliable Sources: Answers are not always grounded in authoritative or trusted enterprise data.
- Terminology Confusion: Inconsistent use of terms across industries or departments can lead to misleading interpretations.
Think of it like a new employee who is smart and eager but doesn’t always have the latest updates. They may speak with confidence but sometimes get things wrong, which quickly undermines trust.
This is why enterprises need Retrieval-Augmented Generation (RAG). Instead of relying solely on static training data, RAG equips LLMs to retrieve fresh, domain-specific information from trusted internal and external sources. By grounding answers in verifiable, real-time data, RAG ensures responses are:
- Accurate and free from hallucinations.
- Current with the latest updates, regulations, or research.
- Reliable, as they are tied to authoritative sources.
- Transparent, with traceability that shows where the information came from.
In short, RAG transforms AI from a generic knowledge generator into a contextual Knowledge AI system that enterprises can trust. It bridges the gap between static training data and the dynamic realities of business, ensuring that every answer is not only correct but also timely, relevant, and aligned with organizational needs.
Read more: How enterprise search boost productivity
What are the types of RAG?
1. Basic RAG: The Foundation of Retrieval + Generation
Basic RAG is the entry point of the framework. It combines a simple retrieval step with generative AI, pulling answers from a fixed set of documents or knowledge bases and then generating a natural-language response. At this level, the system is reactive and task-specific, with limited adaptability.
Think of it as a knowledge-enabled search assistant. It can fetch answers from a FAQ document or a static knowledge base and restate them in a conversational way. While this is valuable, it is also limited, the scope is predefined, and the responses are only as good as the static sources behind them.
Where it works: Customer support chatbots, basic HR helpdesks, or FAQ-driven knowledge portals.
Example: A user asks, “What is the return policy?” Basic RAG retrieves the return policy section from an FAQ and generates a conversational answer like: “You can return any product within 30 days of purchase, provided it is unused and in original packaging.”
2. Advanced RAG: Adding Context and Meaning
Advanced RAG introduces semantic search and contextual understanding. Unlike Basic RAG, which depends heavily on keyword matching, Advanced RAG understands the intent behind the query. It leverages vector embeddings to capture meaning and retrieve the most relevant content, even if phrasing differs from the source.
This is where RAG begins to feel more like a knowledge partner than a simple search tool. It connects the dots across multiple sources, consolidates fragmented data, and presents insights that are richer and more useful.
Where it works: Employee portals, IT support systems, or any knowledge environment where queries are nuanced and answers are dispersed across multiple sources.
Example: An employee asks, “How do I get approval for an international business trip?” Instead of giving three separate policy documents, Advanced RAG consolidates information from HR, finance, and compliance into a single, structured response.
3. Enterprise RAG: Secure, Scalable, and Trusted
Enterprises need more than answers, they need trust, compliance, and scale. Enterprise RAG builds on Advanced RAG by embedding enterprise-grade capabilities. This includes role-based access control (RBAC), encryption, regulatory compliance, audit trails, and deep integration with corporate systems.
It is designed not just to retrieve and generate knowledge, but to do so securely, transparently, and in alignment with organizational policies. At this level, RAG becomes a trusted intelligence system that organizations can deploy across sensitive and regulated functions.
Where it works: Highly regulated industries such as finance, banking, insurance, healthcare, and law.
Example: A financial analyst asks, “What regulatory risks should I flag for our European investment portfolio?” Enterprise RAG retrieves sensitive data from internal systems, applies compliance filters, synthesizes the insights, and provides a citation-backed answer while logging the process for audit.
4. Agentic RAG: The Future of Intelligent Action
Agentic RAG represents the pinnacle of RAG’s evolution. It moves beyond retrieval and generation into the realm of reasoning, planning, and orchestration. Instead of passively fetching and summarizing information, Agentic RAG employs AI agents that actively engage with data, refine queries, validate sources, and even carry out workflows.
As AI evolves into Agentic AI, this makes Agentic RAG less of a search tool and more of an intelligent collaborator. It can break down complex queries into multiple steps, validate responses against multiple sources, adapt dynamically to context, and recommend or even initiate actions.
Key Capabilities of Agentic RAG:
- Autonomous Planning: Breaks down complex queries into smaller subtasks and executes them step by step.
- Self-Correction: Cross-validates data across multiple sources and refines responses to ensure accuracy.
- Dynamic Adaptation: Learns from interactions and adjusts retrieval strategies based on user role, query complexity, or context.
- Multi-Agent Collaboration: Employs specialized AI agents across domains (finance, compliance, HR) to coordinate responses.
- Workflow Orchestration: Goes beyond answers to automate processes, integrate with enterprise systems, and deliver action-ready outputs.
Where it works: High-stakes, knowledge-intensive environments where precision, reasoning, and decision-support are critical.
Example: A CFO asks, “What risks should I highlight in the upcoming board meeting?”
- A Basic RAG system would surface recent financial reports.
- An Advanced RAG system would summarize risks identified across multiple documents.
- An Enterprise RAG system would ensure compliance, access permissions, and citations.
- An Agentic RAG system goes further: it cross-validates financial data, analyzes patterns, identifies emerging risks, drafts mitigation strategies, and generates a board-ready presentation, all grounded in authoritative sources.
Read more about what is Agentic AI, use cases and how it works
What are the benefits of RAG?
Retrieval-Augmented Generation (RAG) is transforming the role of AI in enterprises. It addresses the fundamental shortcomings of standalone large language models and elevates them into trustworthy, context-aware knowledge systems. The benefits of RAG extend across accuracy, security, scalability, and adaptability, creating a foundation that enterprises can build on with confidence.
1. Accuracy and Reliability
The most significant benefit of RAG is its ability to deliver answers that are grounded in factual, verifiable data. Traditional LLMs may generate fluent but incorrect responses because they rely only on static training data. RAG solves this by retrieving authoritative information from trusted sources before generating a response. This grounding mechanism ensures outputs are accurate, relevant, and directly tied to enterprise knowledge assets.
For organizations where misinformation can carry regulatory, financial, or reputational risks, this reliability is indispensable. RAG turns generative AI from a “best guess” system into a dependable engine of truth.
2. Reduction of Hallucinations
Hallucinations, or confident but false statements generated by LLMs, are one of the greatest obstacles to enterprise adoption of AI. RAG directly addresses this problem by ensuring every generated output is tied back to retrieved knowledge. This drastically reduces the likelihood of fabricated content, creating answers that are trustworthy and auditable.
In high-stakes industries like healthcare, finance, or legal services, the reduction of hallucinations is not just a benefit; it is a prerequisite for safe deployment.
3. Transparency and Explainability
In enterprise contexts, trust is not just about accuracy, it is about verifiability. RAG systems can provide citations and references alongside their outputs, showing precisely where information was sourced. This transparency builds confidence among users and gives decision-makers the ability to validate insights before acting on them.
For compliance-heavy environments, this traceability also ensures that knowledge access is defensible and auditable. RAG does not just answer questions, it shows its work.
4. Breaking Down Knowledge Silos
More than 80 percent of enterprise data is unstructured and scattered across disconnected systems. Traditional search systems often fail to unify this knowledge, forcing employees to waste time hunting for information. RAG removes this barrier by retrieving across multiple repositories, both structured and unstructured, and synthesizing insights into a single, coherent response.
The result is the creation of a unified knowledge layer where organizational intelligence flows freely, no longer locked away in departmental silos. This accelerates collaboration, reduces redundancy, and enables enterprises to act on the full breadth of their data assets.
5. Contextual Continuity
Generative AI often struggles to maintain context across multi-step queries or extended interactions. RAG overcomes this by dynamically grounding responses in relevant supporting information at each stage. This ensures continuity, coherence, and logical progression in conversations or analyses.
For enterprises, contextual continuity is essential whether it is a customer service interaction that requires consistency, or a strategic decision-making process that spans multiple perspectives. RAG ensures the conversation stays on track, delivering clear, connected insights rather than fragmented outputs.
6. Strategic Decision Support
RAG is more than a retrieval tool, it is a decision-support system. By integrating information across systems and synthesizing it into contextualized answers, RAG surfaces insights that help leaders make faster, more confident, and more informed decisions.
It does not simply retrieve isolated data points, it identifies relationships, patterns, and implications. For executives, this transforms AI from a passive tool into an active partner in strategic thinking.
7. Streamlined Scalability and Performance
At scale, the ability to process thousands of queries without overwhelming users is critical. Traditional retrieval methods overwhelm employees with long lists of links, leaving them to do the interpretation. RAG eliminates this inefficiency by retrieving, consolidating, and synthesizing into direct, usable answers.
This streamlined approach saves time, reduces cognitive load, and allows knowledge to scale seamlessly across the enterprise. As organizations grow in size and complexity, RAG provides a scalable knowledge infrastructure that keeps pace with demand.
8. Flexibility and Customization
Every enterprise operates in unique contexts, and RAG is designed to adapt. Its retrieval mechanisms can be tuned with domain-specific datasets and aligned with industry-specific needs. This flexibility makes it applicable across verticals, whether in compliance-heavy industries, technical fields, or customer-facing environments.
RAG can also be configured for multilingual use, legal frameworks, or niche technical domains, ensuring it serves not as a generic AI, but as a specialized intelligence system tailored to the enterprise.
The advantages of RAG are both extensive and transformative. It delivers accuracy, minimizes hallucinations, fosters transparency, unifies fragmented knowledge, preserves context, strengthens decision-making, scales seamlessly, adapts to diverse needs, enhances user engagement, optimizes costs, and stays aligned with rapid change. Yet the true breakthrough lies in its evolution into Agentic RAG. By incorporating reasoning, planning, and intelligent action, Agentic RAG elevates AI from a passive provider of information to an active enabler of enterprise intelligence and strategic execution.
Read More: Visualise & Discover RAG Data
Now let's move further and see how Kore.ai has been working with the businesses:
How does Kore.ai transform enterprise search with AI innovation?
Search and Data AI by Kore.ai redefines enterprise search by consolidating fragmented data and transforming it into actionable, trustworthy answers. Powered by advanced Agentic RAG, it delivers precision, scalability, and transparency while maintaining enterprise-grade security and control.
Ingestion: Consolidating Unstructured Data into a Single Source of Truth
Organizations often struggle with knowledge scattered across documents, websites, databases, and applications. Search and Data AI solves this by consolidating all enterprise knowledge into a unified, accessible platform.
- File Uploads: Converts difficult-to-read files and inaccessible directories into concise, actionable answers, while maintaining citations for easy validation.
- Web Crawler: Surfaces information buried deep within websites using automated crawling, with fine-grained control over crawling frequency and depth.
- Connectors: Provides 100+ pre-built and customizable connectors to integrate seamlessly with CRMs, content management systems, databases, and cloud applications.
This ingestion layer ensures that no data remains siloed, creating a comprehensive foundation for enterprise-wide knowledge discovery.
Extraction: Segmenting and Structuring Content for Precision
Not all documents are created equal. Search and Data AI employs sophisticated extraction techniques to ensure that even the most complex or unstructured content becomes searchable, segmentable, and usable.
- Chunk Extraction: Adapts chunking strategies to document layouts, leveraging the best AI models for extraction across different content types.
- Document Layout Studio: Uses AI to structure documents, define chunk boundaries, and build contextual relationships between elements for improved relevance.
- Vectorization and Indexing: Fine-tunes embeddings, selects key fields, and applies pre-trained models like MPNet or LaBSE to maximize retrieval accuracy.
With tailored document segmentation and indexing, enterprises can achieve pinpoint precision in information retrieval, even across highly complex datasets.
Retrieval: Finding the Right Information, Instantly
Search and Data AI goes far beyond keyword-based search by using semantic and hybrid retrieval techniques. The result is faster, contextually relevant answers that reflect the true intent behind a query.
- Fast Answer Retrieval: Converts raw documents into concise, actionable responses while maintaining traceable citations.
- Query Processing: Interprets nuances in datasets and natural language, aligning queries with the vocabulary and structure of enterprise content.
- Flexible Configuration: Offers complete control to fine-tune retrievers, chunk relevance, and semantic weighting for maximum precision.
This ensures that enterprise search is no longer about sifting through results but about finding the right answer immediately.
Generation: Delivering Human-Like, Context-Aware Answers
Once the most relevant data is retrieved, Search and Data AI generates answers that are not only accurate but also clear, contextual, and conversational.
- Human-Like Answers: Combines the strengths of large language models with enterprise-specific data for expert-level responses.
- Accurate AI Responses: Produces reliable, role-aware insights that can be fine-tuned to specific use cases and domains.
- Optimized Efficiency: Uses advanced caching and vectorization to reduce costs, minimize latency, and ensure consistent performance at scale.
This capability transforms search from static results into dynamic, contextual intelligence, where insights are not only delivered but also explained with clarity and prepared for immediate action.
Guardrails: Ensuring Secure, Responsible AI Adoption
Trust is critical for enterprise AI. Kore.ai integrates guardrails and governance mechanisms into every stage of retrieval and generation.
- Bias Control and Safety Filters: Minimize risks by filtering sensitive content and ensuring responses remain compliant.
- Role-Based Access Control (RBAC): Restricts knowledge access to authorized users, maintaining enterprise security.
- Fact-Checking and Transparency: Provides clear traceability to source material, ensuring users understand where each answer comes from.
These safeguards give enterprises the confidence to scale AI adoption while protecting sensitive information and ensuring outputs remain reliable.
The Kore.ai Advantage
With its end-to-end architecture for ingestion, extraction, retrieval, generation, and governance, Search and Data AI transforms enterprise search into a strategic capability.
- Knowledge scattered across silos becomes a unified intelligence layer.
- Complex queries yield concise, actionable answers instead of overwhelming lists.
- Enterprises gain transparency, compliance, and efficiency without sacrificing trust.
By combining Agentic RAG with enterprise-grade features, Kore.ai empowers organizations to move beyond information retrieval to contextual knowledge discovery and intelligent action.
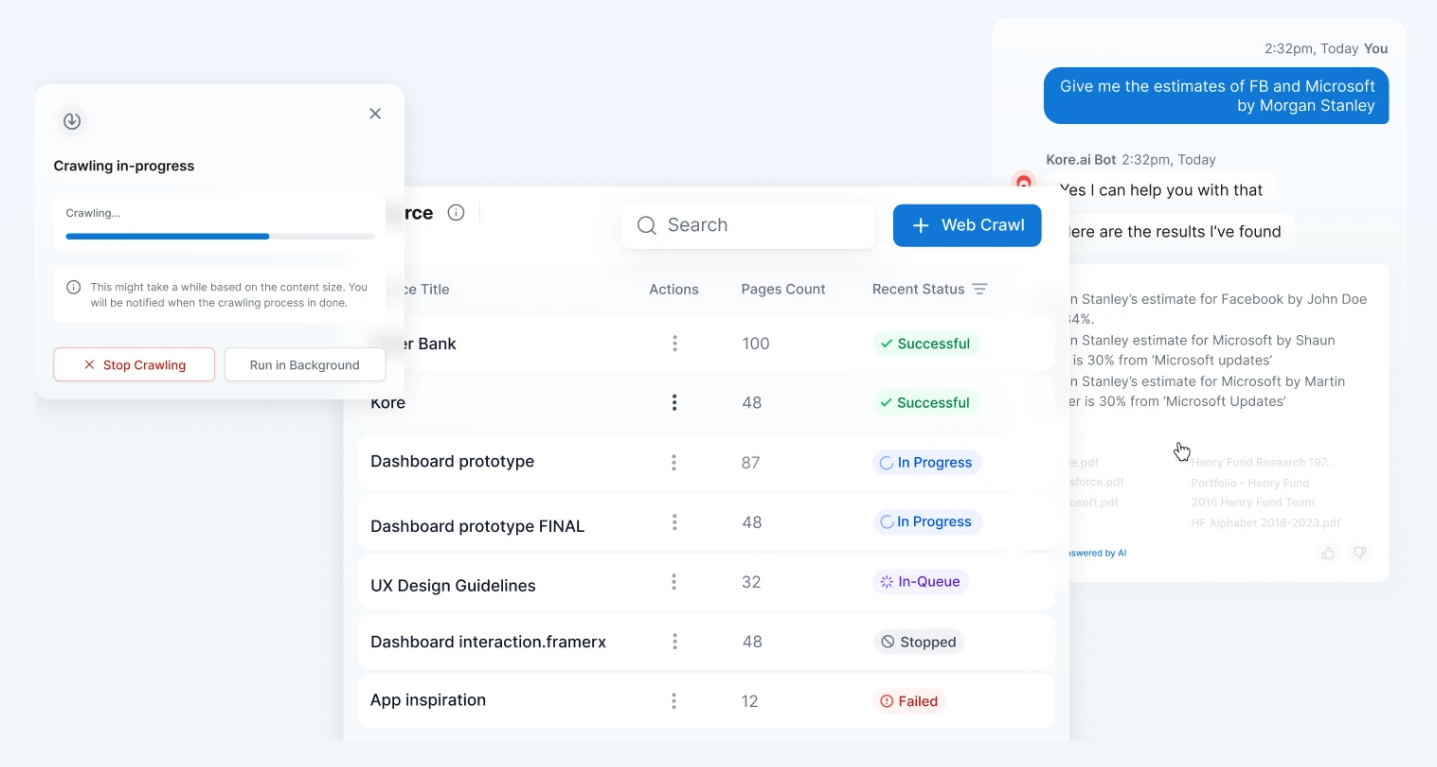
How Kore.ai's AI for Work and Search AI is solving real world problems and delivering ROI for enterprises
SeachAI helping Wealth Advisors Retrieve Relevant Information
AI for Work's impact can be seen in its collaboration with a leading global financial institution. Financial advisors, faced with the daunting task of navigating over 100,000 research reports, found that their ability to provide timely and relevant advice was significantly enhanced. By using an AI assistant built on the Kore.ai platform and powered by OpenAI’s LLMs, advisors could process conversational prompts to quickly obtain relevant investment insights, business data, and internal procedures. This innovation reduced research time by 40%, enabling advisors to focus more on their clients and improving overall efficiency. The success of this AI assistant also paved the way for other AI-driven solutions, including automated meeting summaries and follow-up emails.
AI for Work improves product discovery for global home appliance brand
In another instance, a global electronics and home appliance brand worked with Kore.ai to develop an AI-powered solution that advanced product search capabilities. Customers often struggled to find relevant product details amidst a vast array of products. By utilizing RAG technology, the AI assistant simplified product searches, delivering clear, concise information in response to conversational prompts. This significantly reduced search times, leading to higher customer satisfaction and engagement. Inspired by the success of this tool, the brand expanded its use of AI to include personalized product recommendations and automated support responses.
AI for Work proactively fetches relevant information for live agents
Kore.ai's AgentAI platform further exemplifies how AI can enhance customer interactions. By automating workflows and empowering IVAs with GenAI models, AgentAI provides real-time advice, interaction summaries, and dynamic playbooks. This guidance helps agents navigate complex situations with ease, improving their performance and ensuring that customer interactions are both effective and satisfying. With the integration of RAG, agents have instant access to accurate, contextually rich information, allowing them to focus more on delivering exceptional customer experiences. This not only boosts agent efficiency but also drives better customer outcomes, ultimately contributing to increased revenue and customer loyalty.
AI for Work and Kore.ai's suite of AI-powered tools are transforming how enterprises handle search, support, and customer interactions, turning data into a powerful asset that drives productivity and enhances decision-making.
For more detailed information, you can visit the Kore.ai AI for Work page
The promising future of RAG
Retrieval-Augmented Generation (RAG) is emerging as one of the most powerful frameworks to overcome the current limitations of generative AI. While traditional large language models excel at producing fluent responses, they often lack grounding in real-world data, leading to inaccuracies or outdated answers. RAG addresses this gap by combining the generative strength of LLMs with retrieval mechanisms that pull in authoritative, up-to-date knowledge at the moment of the query.
This evolution positions RAG not just as a tool for better search, but as a foundation for intelligent reasoning systems. By anchoring AI outputs in verified data, RAG moves beyond simple text generation into a future where AI can provide contextually relevant, trustworthy, and actionable insights. It transforms AI from an “information echo” into a partner capable of supporting decision-making with confidence.
As enterprises accelerate their shift from experimental pilots to enterprise-wide adoption of AI, RAG is increasingly being recognized as AI done right. It offers a structured pathway to mitigate risks like hallucinations, enhance transparency with citations, and maintain compliance with enterprise security standards. Most importantly, its ongoing evolution into Agentic RAG promises an even more transformative future. With the ability to plan, reason, validate, and orchestrate actions, Agentic RAG will elevate enterprise AI from passive knowledge retrieval to proactive, outcome-driven intelligence.
In short, the future of RAG lies in its ability to ground generative AI in reality, enabling systems that are not only accurate and reliable, but also capable of evolving into trusted collaborators across every domain of enterprise knowledge.
Explore more how Seach and Data AI can transform your enterprise search or product discovery on your website.




