Search across silos. Automate workflows. Orchestrate AI agents. Govern with confidence.
Leverage Agentic capabilities to empower customers and create personalized experiences.
Streamline knowledge-intensive business processes with autonomous AI agents.
.webp)

Join Kore.ai’s re:imagine Tour in Dallas on 16th October, 2025. Discover how enterprises are scaling AI with real use cases and expert insights.
Join Kore.ai’s re:imagine Tour in Dallas on 16th October, 2025. Discover how enterprises are scaling AI with real use cases and expert insights.
.webp)
AI Agent Evaluation: Reliable, Compliant & Scalable AI Agents
AI agents have already crossed the tipping point in the enterprise. We are no longer talking about pilots or proofs of concept. We are talking about large-scale production. By 2025, more than 60% of enterprises will have at least one AI agent in production, managing IT tickets, payments, and frontline support. Gartner predicts that by 2027, 40% of enterprise workloads will run on autonomous AI agents, and by 2028, one-third of workflows will involve them.
Deployment is no longer the challenge. AI agent evaluation is. For enterprises, evaluating AI agents has become the foundation of trust, reliability, compliance, and business value.
The promise is clear. AI agents reduce manual effort, accelerate decision-making, and create adaptive digital experiences. Unlike traditional chatbots or RPA, they can reason, invoke tools, and act across workflows. Because they are probabilistic systems, outputs vary with context, prompts, and models. That flexibility makes them powerful and unpredictable.
This unpredictability is why a structured AI agent evaluation framework is now critical. Without it, enterprises risk deploying agents that hallucinate, misuse tools, expose sensitive data, or fail in mission-critical workflows. Accenture survey found that 77% of executives view trust, rather than adoption, as the primary barrier to scaling AI.
For IT leaders, the key question is no longer “Can we deploy AI agents?” The real question is:
“How do we evaluate AI agent performance with the right metrics and frameworks to ensure reliability, compliance, and enterprise value?”
Table of contents
- What is AI Agent Evaluation
- Why is AI Agent Evaluation critical for enterprises?
- What is ‘AI Observability’ in agent evaluation, and why does it matter?
- How do you measure AI Agent performance?
- Types of Agent evaluations and testing practices
- How should enterprises structure an Agent Evaluation Framework?
- The AI Agent Evaluation Framework in action
- What is the future of AI Agent Evaluation?
- Final thoughts: Agent evaluation will define enterprise trust in the future
- Enterprise-grade AI Agent Evaluation with Kore.ai Agent Platform
What is AI Agent Evaluation?
AI Agent Evaluation is the systematic process of assessing how effectively AI agents perform across multiple dimensions, including accuracy, groundedness, reliability, compliance, transparency, and business impact. Unlike traditional software, which produces deterministic outputs, AI agents are probabilistic and adaptive. Their responses vary depending on prompts, context, data, and workflows, making continuous evaluation essential for enterprise-scale trust.
At its core, Agent evaluation ensures that AI Agents:
- Generate grounded and factual responses, reducing the risk of hallucinations and misinformation.
- Avoid bias and harmful outputs, ensuring fairness, inclusivity, and ethical AI adoption.
- Respect safety and compliance guardrails, such as data protection, access control, and regulatory standards.
- Invoke the right tools, APIs, and workflows reliably, even under stress, ambiguity, or scale.
- Deliver measurable business outcomes, such as faster resolution times, higher containment rates, reduced costs, and improved customer or employee satisfaction.
- Provide transparency and explainability, with decision paths and reasoning chains that can be audited by IT leaders, business stakeholders, and regulators.
- Adapt and improve continuously, staying aligned with evolving business goals, datasets, and compliance requirements.
AI agent evaluation is not a one-time QA step. It is a continuous, lifecycle discipline embedded across build, test, release, and production. By combining technical testing, AI observability, human feedback loops, and business KPI tracking, enterprises ensure that agents remain reliable, transparent, and enterprise-ready.
In short, Agent evaluation safeguards against hallucinations, bias, and compliance failures, while proving that AI agents can deliver trustworthy, explainable, and value-driven performance at scale.
Why is AI Agent Evaluation critical for enterprises?
Enterprises grew up on deterministic software, where the same input always produced the same output, making testing simple. AI agents aren’t deterministic. They are probabilistic, context-sensitive systems that reason, invoke tools, fetch knowledge, and make decisions in real-time.
Take a basic IT support request: “reset my password.” One run may correctly invoke the API and finish in seconds; another may misread intent, loop, or provide irrelevant guidance depending on phrasing, history, or system state. This variability is both their power and their risk.
That’s why Agent evaluation can’t be a one-off pre-launch test. It must be a continuous discipline spanning build, test, release, and production. Without it, enterprises face real risks: hallucinations, misrouted workflows, mishandling of PII, or overloaded backend APIs.
The fallout is already familiar to IT leaders: trust erodes, costs rise, and compliance exposure grows. A credible Agent evaluation framework must measure far more than “Was the answer accurate?” It must ask:
- Did the agent choose the right tools?
- Did it follow enterprise policy?
- Did it protect sensitive data?
- Did it deliver the intended business outcome?
In short, evaluating AI agents means assessing performance in terms of round, reliability, safety, compliance, and operational impact, not just textual correctness. That is the only way to measure AI agent performance credibly at enterprise scale.
What is 'AI Observability' in Agent evaluation and why does it matter?
AI Observability refers to transforming production behavior into evidence that enterprises can trust. It is the instrumentation that captures logs, traces, and outcomes to ensure transparency and compliance. Once an agent goes live, the real test begins, and AI observability is what makes evaluation continuous, not static.
What AI observability captures:
- Raw inputs and recognized intents
- Tool and API calls
- Outputs and confidence scores
- Latency and outcomes
Beyond raw data, AI observability enables end-to-end traces so developers can replay the agent’s reasoning path, seeing not just what it decided, but why. Real-time dashboards then surface signals such as latency spikes, failure clusters, policy hits, or drift, allowing IT teams to act before small issues escalate into failures.
Why it matters:
- Compliance & Auditability - Enterprises in regulated industries need traceable logs to satisfy auditors and regulators.
- Trust & Reliability - Transparent AI observability builds confidence for both IT leaders and end-users.
- Operational Efficiency - Early detection of drift or latency spikes prevents costly outages and performance degradation.
In short, AI observability is accountability. Without it, evaluation is blind. With it, AI agent evaluation becomes continuous, transparent, and auditable, keeping performance aligned with enterprise policy, compliance requirements, and business goals.
How do you measure AI agent performance?
When enterprises first test large language models (LLMs) or generative AI applications, evaluation often focuses narrowly on accuracy or fluency. Did the model answer correctly? Did it sound natural?
These checks matter, but they’re nowhere near sufficient for AI agent evaluation. Unlike standalone models, agents are autonomous, multi-step systems. They orchestrate workflows, invoke APIs, retrieve knowledge, and deliver structured results. Their effectiveness and their risks extend far beyond whether a sentence looks right.
This raises the broader question for enterprise leaders:
How do you measure AI agent performance across all the dimensions that matter to operations?
1. Technical Metrics - Reliability and Scale:
The real question isn’t whether an agent works once in testing, it’s whether it performs consistently under production pressure. Enterprises need to know if agents can withstand peak loads, recover from cascading API failures, and handle latency without disrupting mission-critical workflows like trading or patient support.
2. Quality Metrics - Trust and Experience
Accuracy alone doesn’t guarantee adoption. What counts is whether the agent maintains context over multi-turn conversations, avoids hallucinations, and reflects the organization’s knowledge and brand standards. Even small lapses can undermine user confidence.
3. Safety & Compliance Metrics - Enterprise Protection:
Evaluation must demonstrate that agents respect guardrails by design. This includes masking sensitive data, running bias checks, and enforcing role-based access. A single compliance slip can escalate into fines, lawsuits, or reputational damage.
4. Business Metrics - Real Enterprise Value:
Ultimately, Agent evaluation only matters if it proves ROI. Enterprises track whether agents reduce time-to-resolution, boost containment, lower cost per interaction, or drive conversions and retention. If these levers don’t move, the agent isn’t delivering enterprise value.
Accuracy alone is never enough. Only by measuring technical resilience, quality of experience, safety/compliance, and business outcomes can enterprises trust AI agents at scale.
Types of Agent evaluations and testing practices
Evaluating AI agents is not a single activity but a discipline composed of different evaluation types, each targeting a specific dimension of performance, reliability, or compliance. Enterprises need to combine these perspectives to capture the true complexity of agent behavior in production.
Types of AI Agent evaluations
AI agent evaluations are a critical part of the enterprise AI lifecycle, designed to measure how effectively an agent performs across logic, reasoning, compliance, and security dimensions. These evaluations help organizations verify that their AI systems function accurately, handle data securely, and align with business and regulatory requirements.
By assessing everything from code logic and output accuracy to domain alignment and guardrail adherence, enterprises can ensure that their AI agents are reliable, trustworthy, and production-ready.
The table below summarizes the main types of Agent evaluations, explaining how each one contributes to building safe, compliant, and high-performing intelligent systems.
Testing practices for enterprise AI Agents
Testing practices for enterprise AI agents ensure that intelligent systems maintain their performance, reliability, and compliance as they evolve. These practices act as the foundation of AI quality assurance, verifying that agents consistently deliver accurate, safe, and contextually appropriate results across updates, workflows, and integrations.
By applying structured test scenarios, real-world data, regression testing, and LLM change management, enterprises can continuously monitor and enhance agent performance.
The table below highlights the key AI testing practices used by enterprises to maintain trustworthy and high-performing AI systems throughout their lifecycle.
Summary
Without structured evaluation types and rigorous testing practices, enterprises risk treating agent validation as a one-time exercise. In reality, evaluation must evolve in lockstep with agents themselves, adapting to new models, new workflows, and new compliance demands. By combining multi-dimensional evaluation types with robust testing disciplines, organizations ensure their AI agents remain reliable, secure, and aligned with enterprise value at scale.
These evaluation types and testing practices set the foundation. The next step is to explore how enterprises can integrate them within a structured framework.
How should enterprises structure an Agent evaluation framework?
As enterprises scale AI agents from pilots to production, the lack of a systematic AI agent evaluation framework becomes the biggest barrier to responsible adoption. Traditional QA cannot handle probabilistic, adaptive systems integrated into complex workflows.
A robust framework balances technical rigor, business relevance, and regulatory accountability, and rests on five pillars:
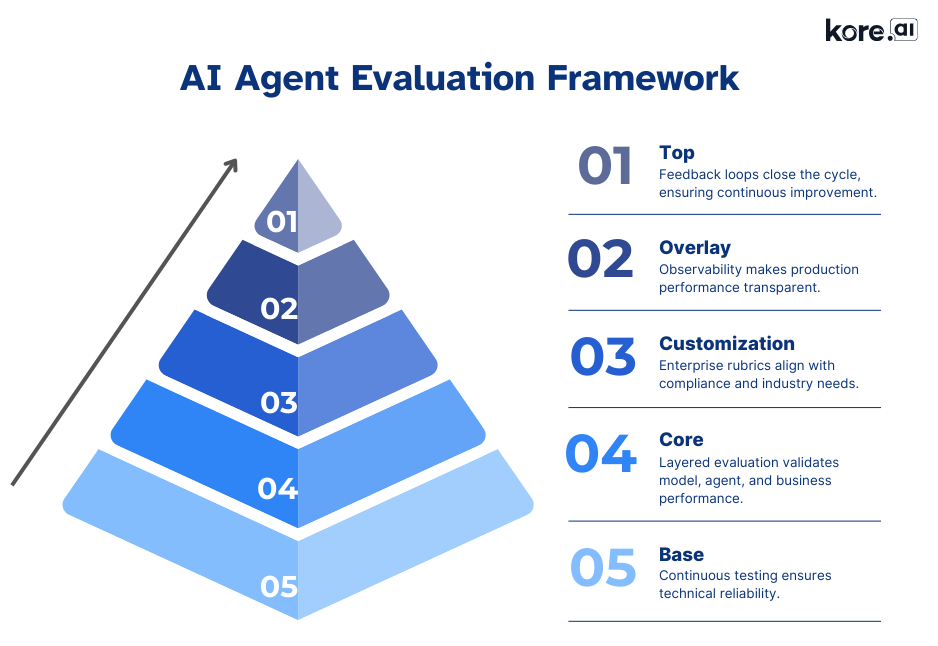
1. Foundation: continuous testing and benchmarking
- Combine synthetic and real-world datasets to test both common and edge cases.
- Integrate evaluation into CI/CD pipelines so every release is validated before deployment.
- Apply stress and adversarial testing to expose vulnerabilities (e.g., noisy inputs, jailbreak attempts).
Takeaway: Reliability must be engineered before production, not after.
2. Layered evaluation across model, agent, and business levels
Evaluation must occur at multiple levels to capture the true complexity of agent behavior:
- Model-level: Check linguistic quality, factual grounding, bias, and hallucination rate.
- Agent-level: Validate tool invocation, workflow orchestration, and task completion.
- Business-level: Measure outcomes linked to KPIs - resolution time, containment, CSAT/NPS.
Takeaway: Evaluation must go beyond answers; it must test reasoning, workflows, and business outcomes.
3. Enterprise customization
- Define contextual rubrics: what success means in your industry.
- In healthcare, patient safety must dominate evaluation rubrics.
- In finance, auditability and zero tolerance for hallucinations are critical.
- Anchor evaluation to compliance frameworks (GDPR, HIPAA, SOX).
- Use role-based scoring for employees, end-users, and auditors.
Takeaway: Evaluation only matters if it reflects your industry’s risks and rules.
4. AI observability and monitoring
Deployment is where the real test begins. Continuous monitoring transforms evaluation from a pre-launch gate into an ongoing discipline.
- Capture comprehensive logs: inputs, intents, tool calls, latency, outputs.
- Ensure traceability of every decision path, not just what the agent did, but why.
- Provide real-time dashboards for IT and compliance leaders to detect drift, failures, or spikes.
Takeaway: Deployment is the beginning of evaluation, not the end.
5. Feedback and continuous improvement
- Build automated feedback loops into prompts, fine-tuning, and workflows.
- Keep human-in-the-loop reviewers for brand, tone, and ethics checks.
- Establish governance checkpoints (weekly, monthly, quarterly) tied to enterprise risk.
Takeaway: Agents that don’t learn continuously will fall behind enterprise needs.
Together, these five pillars transform AI agent evaluation from ad-hoc testing into a disciplined enterprise framework, ensuring agents are reliable, compliant, and aligned with business outcomes at scale.
The AI Agent evaluation framework in action
Think of the Agent evaluation framework as a pyramid:
What is the future of AI Agent Evaluation?
AI agent evaluation is rapidly evolving from ad-hoc testing into a continuous, standards-driven discipline. As enterprises deploy agents into mission-critical workflows, the focus is shifting beyond accuracy to workflow reliability, compliance, and interoperability.
Emerging protocols such as the Model Context Protocol (MCP) are already standardizing how agents interact with external tools and enterprise systems. At the same time, frameworks like Agent2Agent (A2A) are enabling collaboration between agents across platforms. Meanwhile, hyperscalers such as AWS, Microsoft, and Google are introducing their own agent runtimes, raising the stakes for cloud-agnostic evaluation frameworks.
In this future, Agent evaluation will be defined by three characteristics:
- Dynamic: Continuous monitoring across live environments ensures agents adapt in real time, not just at launch.
- Explainable: Every reasoning step, tool call, and workflow can be traced, giving IT leaders operational clarity and regulators the auditability they demand.
- Standardized: Interoperable frameworks across vendors and industries prevent lock-in and enable consistent trust in performance.
Enterprises will no longer ask: “Was the answer correct?” Instead, they will measure whether the entire reasoning chain, tool invocation, and decision-making process was trustworthy, explainable, and auditable. AI Observability, logging, and tracing will make every interaction transparent, allowing IT leaders to pinpoint failures instantly and giving regulators the evidence to validate compliance.
Final thoughts: Agent evaluation will define enterprise trust in the future
Agent evaluation is no longer optional; it is the backbone of enterprise trust in generative AI systems. As standards like the Model Context Protocol (MCP) and Agent2Agent (A2A) emerge, and as hyperscalers roll out their own agent runtimes, the central challenge for enterprises is shifting from “Can agents work?” to “Can they work reliably, securely, and at scale?”
The next generation of evaluation will be:
- Dynamic - embedded into every stage of the lifecycle.
- Transparent - explainability and observability by default.
- Continuous - a discipline, not a one-off QA exercise.
Enterprises will measure not just response accuracy, but also reasoning chains, tool calls, workflow execution, compliance alignment, and business outcomes. They will expect traceability and auditability by default, ensuring every AI-driven decision can be explained, optimized, and trusted.
In short, AIgent evaluation will evolve into the DevOps of enterprise AI, underpinning every stage of the lifecycle, from design to deployment to monitoring.
Enterprise-grade AI Agent Evaluation with Kore.ai Agent Platform
For enterprises ready to operationalize AI responsibly and at scale, the Kore.ai Agent Platform ensures that evaluation is not an afterthought, but a built-in discipline.
Kore.ai Evaluation Studio: Purpose-built for trustworthy AI
The Evaluation Studio assesses both AI models and agentic AI applications to guarantee that responses are accurate, relevant, compliant, less biased, and reliable across build, test, and production. It transforms evaluation from a one-time activity into a continuous lifecycle process.
Key capabilities include:
- AI Response Accuracy
Detect and reduce hallucinations early. During build time, developers can fine-tune responses using test datasets or apply human feedback loops to continuously improve performance. - Relevance Analysis
Verify whether agent and model outputs truly address user intent. Teams can apply prebuilt evaluators or design custom evaluators to measure how closely responses align with enterprise goals and customer expectations. - Agent + Tool Evaluators
Ensure Agents behave as designed, making the right choices about which tools to invoke and when. Organizations can simulate domain-specific user scenarios to confirm that agents remain dependable in real-world conditions.
End-to-end evaluation across the lifecycle
Evaluation Studio does not work in isolation. It integrates with the Kore.ai platform’s monitoring and governance layer:
- Real-time tracing of reasoning chains and tool calls, giving full transparency into agent decisions.
- Audit-ready logs for compliance and regulatory reporting.
- Customizable dashboards for IT teams and business leaders to measure KPIs like CSAT, containment, or ROI.
- Continuous regression testing that ensures upgrades do not compromise quality.
Why this matters for enterprises
With Kore.ai, enterprises do not just deploy agents. They govern them. Evaluation studio and platform together provide full AI observability and accountability, turning every agent interaction into something measurable, explainable, and tied to business outcomes. This is what makes AI agents not only deployable but dependable at scale.
To learn more, explore the Kore.ai Agent Platform
FAQs
Q1. What is AI agent evaluation?
AI agent evaluation is the structured process of measuring how AI agents perform across technical, quality, safety, compliance, and business metrics. It ensures responses are grounded, reliable, unbiased, and enterprise-ready, building trust at scale.
Q2. Why is Agent evaluation important?
AI agents are probabilistic and adaptive, meaning their behavior can vary with context, prompts, or workflows. Without evaluation, enterprises risk hallucinations, bias, or compliance failures. Continuous evaluation ensures consistency, reliability, and business value in production.
Q3. How do you evaluate an AI agent's performance?
Performance is evaluated using a multi-dimensional framework that tests:
- Technical resilience (latency, throughput, error handling)
- User experience quality (relevance, coherence, groundedness)
- Safety and compliance (bias checks, PII protection, policy adherence)
- Business outcomes (CSAT, ESAT, containment, ROI)
Q4. What are the key AI agent performance metrics?
Key metrics include latency, error rate, tool invocation accuracy, groundedness, hallucination rate, bias detection, PII protection, containment rate, CSAT/ESAT scores, and revenue impact. Together, these validate both operational reliability and enterprise value.
Q5. How is AI agent evaluation different from traditional software testing?
Traditional software is deterministic, producing the same output for the same input. AI agents are probabilistic and context-sensitive, requiring continuous monitoring, observability, and adaptive evaluation to ensure trustworthiness, compliance, and scalability in real-world conditions.




